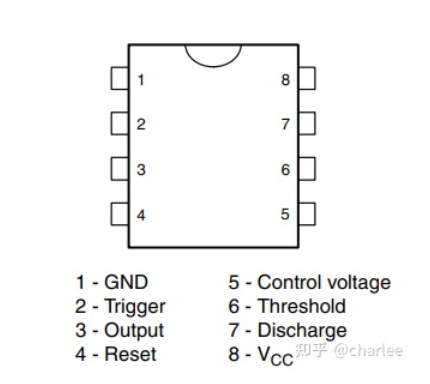
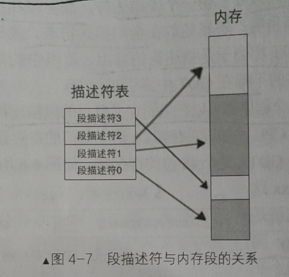
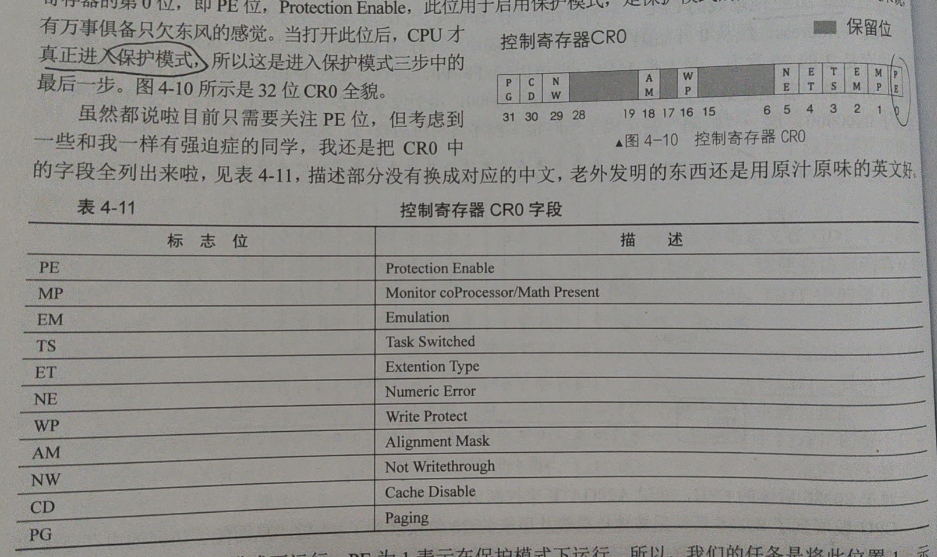
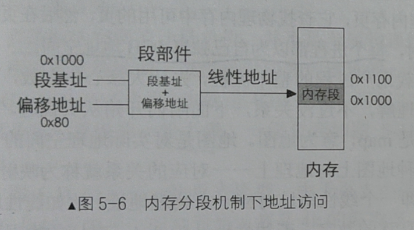
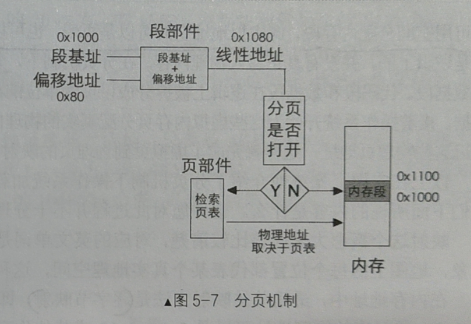
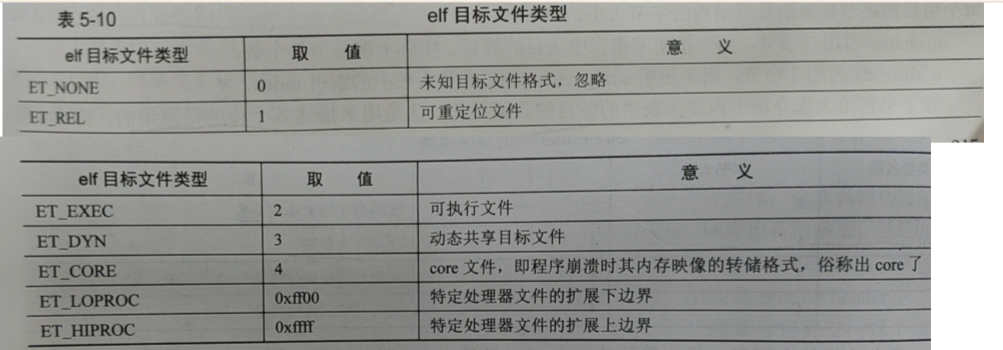
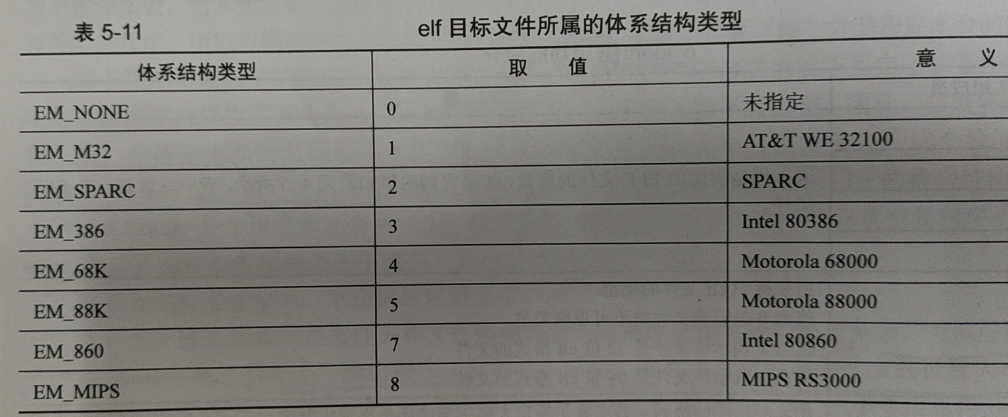
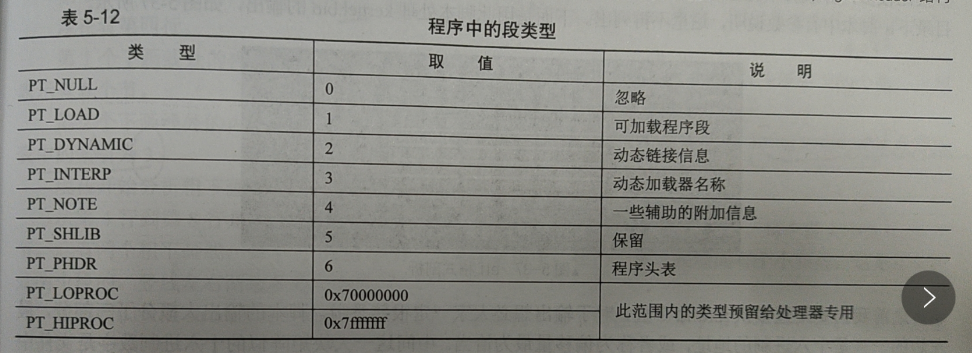
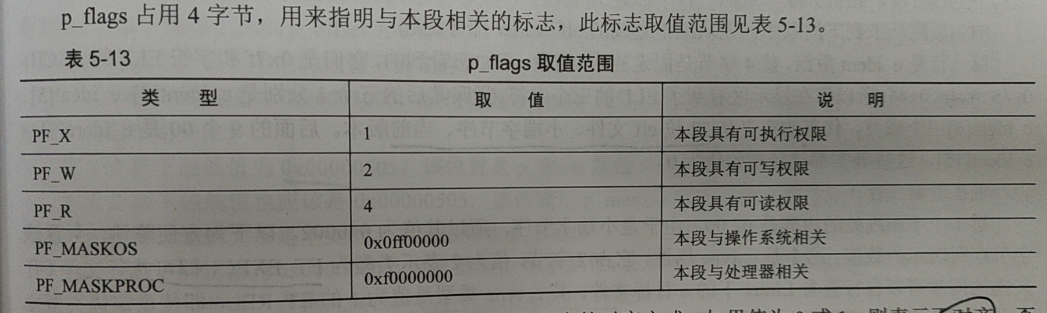
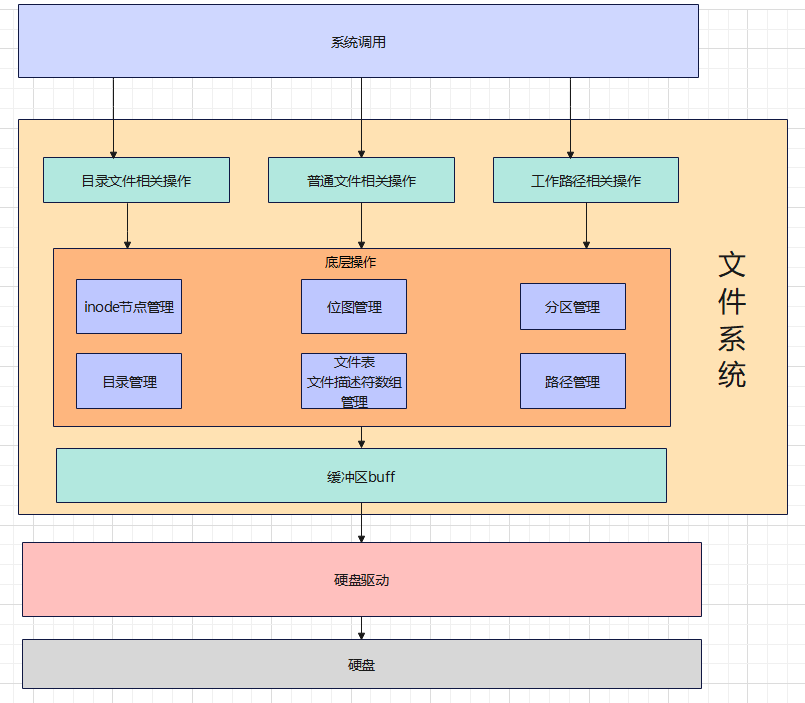
整体设计方案
本文件系统仿照Linux的ext2文件系统设计
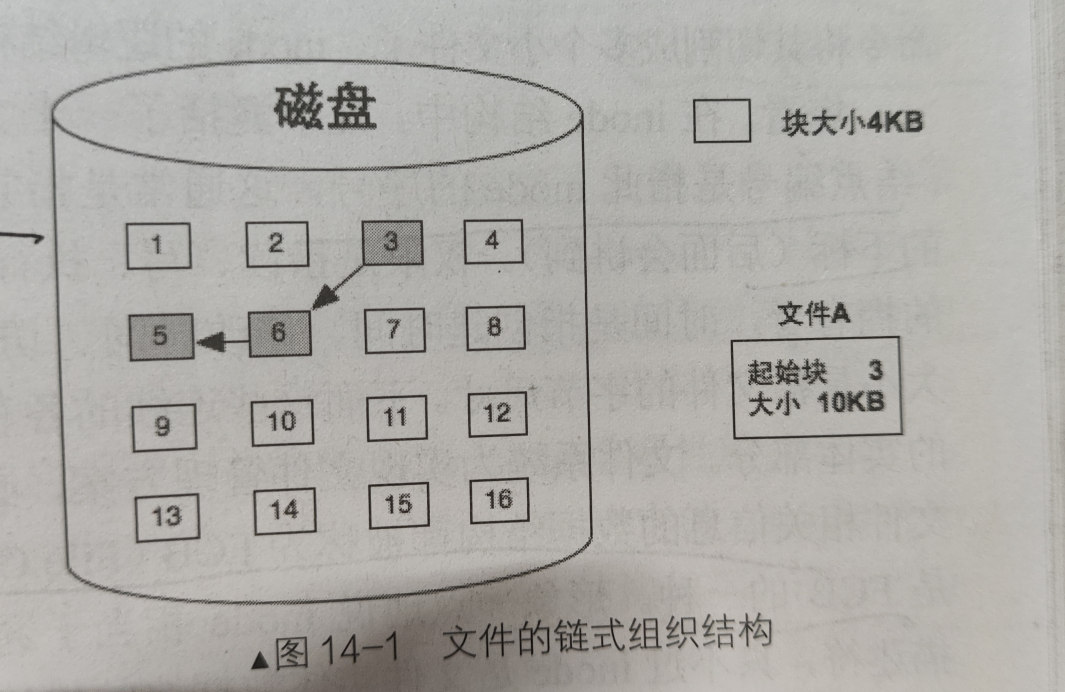
文件的读写单位——块
硬盘的读写单位是扇区,但是由于硬盘读写速度较慢,所以当我们读写文件时,不是一个一个扇区进行读写,而是凑齐数个扇区一起读写,我们将其称为块。
因此 块是文件的读写单位, 一个块包含数个扇区(一定是扇区的整数倍)
文件的本质——inode
文件其实就是存储在硬盘上的数据,并且是以块为单位进行读写
我们关注文件,本质上是关注数据在硬盘上存储的块的组织方式(数据块在硬盘上是不连续的)
FAT文件系统曾采用链式结构进行组织(每个块的最后存储下一个块的地址),但由于访问文件中某一个块时都得从头遍历,最终放弃使用该文件系统
UINX操作系统采用索引结构inode进行组织,后来Linux的ext2文件系统也是模仿该组织形式,本项目同样采用索引结构inode
索引结构说简单点就是一个数组,每一个元素就是每一个块,比起链式结构来说,访问某个特定的块无需从头遍历
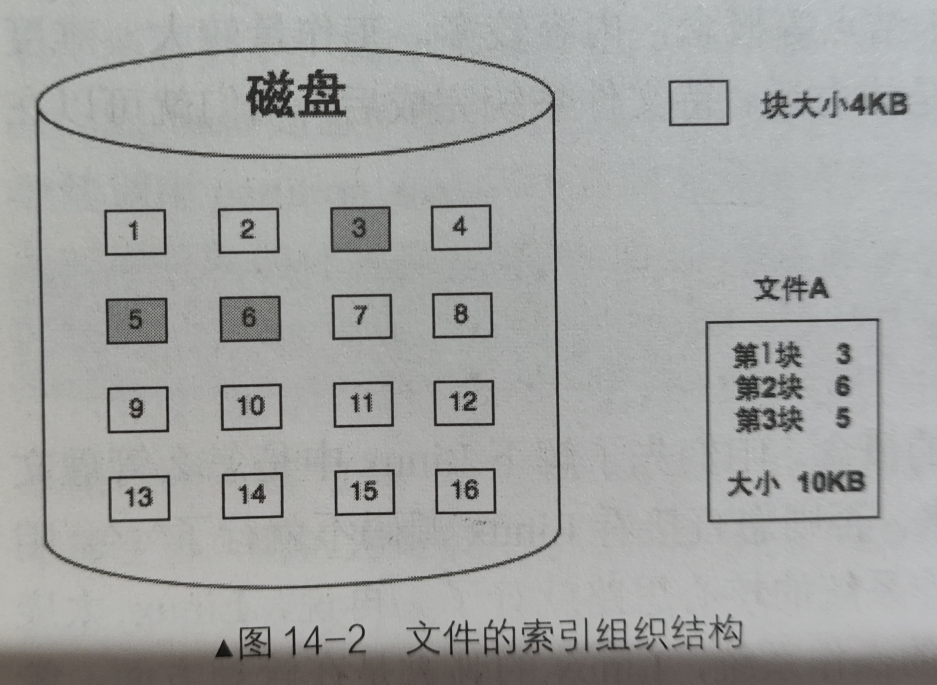
所以现在看来inode就是一个数组,数组元素就是块地址,我们根据数组的索引可以方便的寻找到对应块的地址
然而真正的inode并非这么简单,它还需要扩展两点
文件过大怎么办?——引入间接块索引表指针
假设我们一个indoe包含15个索引项,其中前面12个是直接块指针。当一个文件大小小于等于12块时就可以只使用前12个索引项解决问题。
当文件大小超越12个块了怎么办?
我们把第13个索引项作为一级间接块索引表指针,它指向一级间接块索引表(单独占一个块),而一级间接块索引表上面又存储着256个直接块地址。于是文件最大可达12+256=268个块
当文件超越268个块了怎么办?
我们把第14个索引项作为二级间接块索引表指针,它指向256个一级间接块索引表指针,于是文件最大可达12+256+256*256个块
文件大小还是太大了怎么办?
我们把第15个索引项作为三级间接块索引表指针,它指向256个二级间接块索引表指针,于是文件最大可达12+256+256*256+256*256*256个块
一般的文件无法超越这个大小。再大的文件就只能呢使用mv命令分割成数个小文件
inode真的只是一个数组吗?
其实不然,inode最核心的部分确实是块数组。但inode的本质其实是文件的元信息。除了包含块数组(描述文件存储位置),还包含一些其他的元信息,例如:i结点编号(inode的唯一编号)、文件大小、权限、创建时间、属主等等
结合上述两点扩展,现在真正的inode如下图所示:
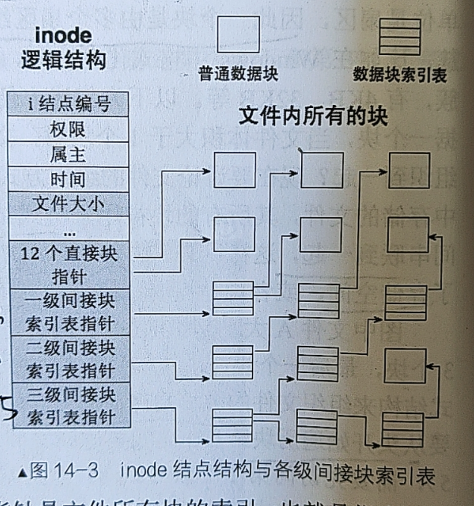
所有文件的集合——inode数组
一个inode就是一个文件,我们将所有inode的编号作为索引,inode地址作为元素,构成一个inode数组。
现在所有的inode地址信息都集合在inode数组里了,只需要提供inode编号,我就可以去查找具体的inode
文件的分类
文件包含两大类:目录文件 和 普通文件
日常口语中的文件大多指的是普通文件,但本文讨论的文件既包括普通文件也包括目录文件
目录也是文件?对的,在ext2文件系统中,目录文件和普通文件一样都算文件,它们的真面目也都是inode
唯一的区别就是数据块存储的内容不同。目录文件的数据块存储的内容是目录项,而普通文件的数据块存储的内容是普通数据。
二者对外表现都是inode,也就是说,在没有外来信息(上级目录)提供帮助的情况下,一个inode就是一个inode,你永远无法区分它到底是目录文化还是普通文件。
PS:目录项是什么?目录项是目录文件下的单位表项,它将inode编号、文件名、文件类型三者关联起来,如图:

完整的FCB——inode+目录项
FCB全称是文件控制块,只要是用于管理、控制文件相关信息的数据结构都称为FCB
ext2文件系统里的FCB包含inode和目录项两大数据结构,也就是说只凭借二者就可以完整的组织起所有的文件
inode和目录项的关系参照下图:
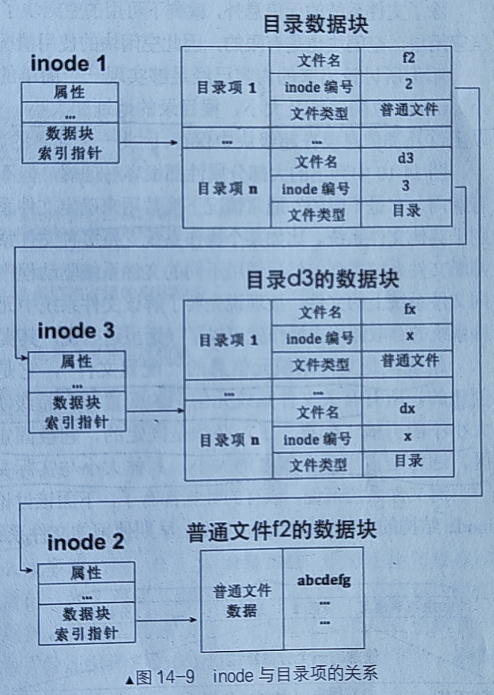
我们假设inode1是根目录,是一切最开始的文件。由于根目录文件的位置是固定不动的,所以我们能确定它是目录文件而不会混淆,根目录文件里的数据块存储的理所当然是一系列目录项。
而目录项上记载了文件的类型、文件名称、inode编号
我们的inode2类型是普通文件,所以我们可以根据inode编号2在inode数组中查找到对应的inode地址。然后根据块指针找到硬盘上对应的数据块,并读取数据块上的普通数据
我们的inode3类型是目录文件,所以我们可以根据inode编号3在inode数组中查找到对应的inode地址。然后根据块指针找到硬盘上的对应块,并读取数据块上的目录项
现在,假设我们有一串完整的文件地址,例如:D:\CodeSet\myBlog\source\img\SimpleOS-7-文件系统\img11.png
我们就可以根据上诉方法一步一步递归查找,最后寻找到正确的文件
文件系统的布局
一个文件系统就是一个分区,而每一个硬盘分区的空间大小是有限的。不论是inode还是用于存储数据的空闲块都需要占据同一个分区的空间。因此,一个分区所拥有的inode和空闲块都是有限的,而且需要使用位图数据结构进行管理。
综上,一个文件系统需要inode位图、空闲块位图、inode数组、固定的根目录位置,以及还需要一个用来描述该文件系统元信息的超级块
文件系统在磁盘上的布局如下图所示:
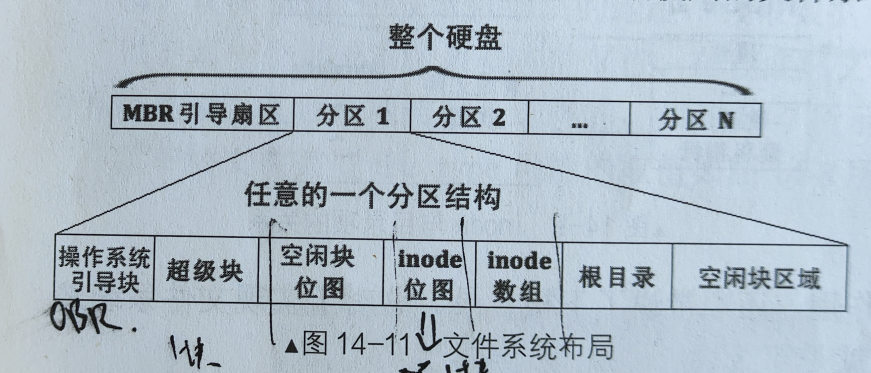
其中超级块的结构如下图所示:

至此,整个文件系统的布局已经完整,文件之间的组织方式也已经清晰,大体上如下图:
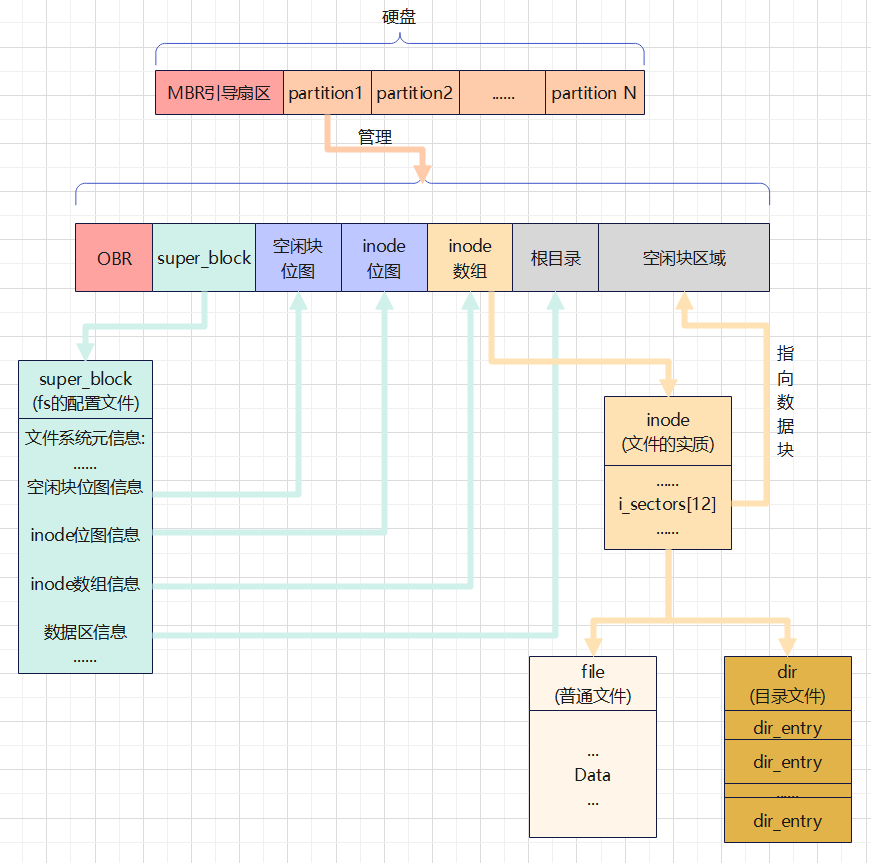
PS:一个操作系统具有多个分区,也就是多个文件系统,但初始化时往往只会挂载一个主要的文件系统,也就是当前文件系统
进程间的文件操作
众所周知,一个电脑允许多个进程,一个进程又允许多次打开同一个文件或者打开多个不同的文件。并对文件进行操作。
我们该如何处理 多进程 与 多文件 之间的关联问题?
为此,我们引入了如下概念:文件描述符、文件结构、文件表、inode缓冲队列
它们之间的逻辑关系如下图所示:
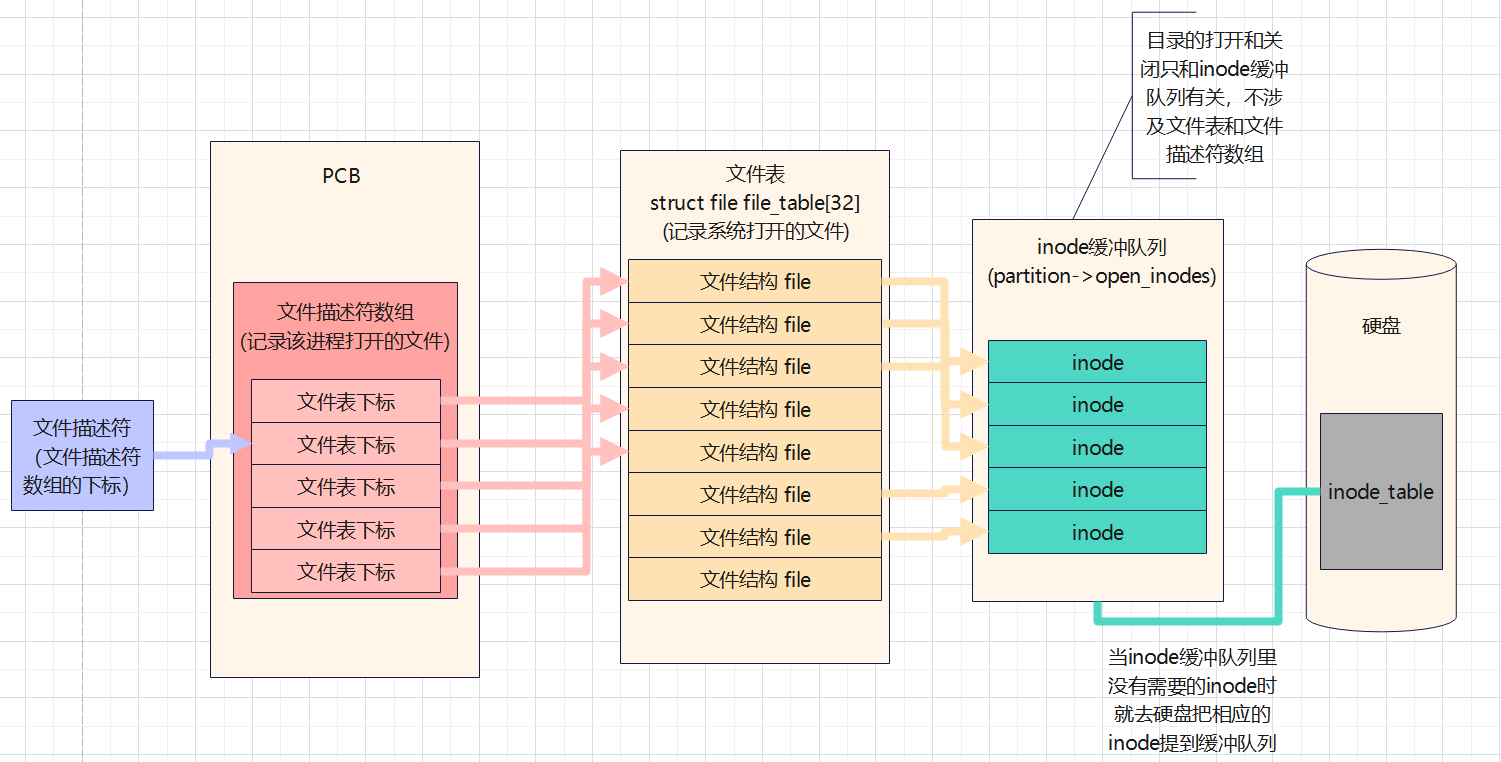

文件表
文件表就是文件结构file集成的数组。文件表用于记录系统打开的文件(不能超过规定的系统最大打开文件数)
文件表存在于内存当中。每当系统初始化后(主文件系统已挂载),系统内存将会申请文件表所需的空间,并为数组的每一个元素置NULL,直到有文件被打开时,文件表会填写相应的文件结构file并返回下标(一般来说下表0被留给标准输入、1被留给标准输出、2被留给标准错误)。
inode缓冲队列
每一个被挂载的分区都会初始化自己的indoe缓冲队列,它是该分区所有被打开的文件inode组成的缓冲队列(同一个文件被打开多次的情况下,也只会有唯一一个inode存在该队列,只不过该inode上记载着被打开的次数)
inode缓冲队列也是存在于内存当中。
文件描述符
每一个PCB(进程控制块)都会有一个文件描述符数组,用于记录该进程打开的文件(不能超过规定的进程最大打开文件数)。
该文件描述符数组存储的元素即是相对应的文件结构在文件表中的下标
当一个进程需要打开一个新文件时会经历如下步骤:
1. 进程提供新文件的inode号作为参数调用函数
2. 检测inode缓冲队列中是否存在该inode,如果存在则inode记录的文件打开次数加一,如果不存在则从硬盘里寻找该inode并加入缓冲队列
3. 从文件表file_table中获取一个空闲位,并填入新构建的文件结构file(指向inode),然后返回该文件结构在文件表中的下标
4. 进程PCB取得下标,存储在文件描述符数组中,并返回对应的文件描述符数组下标(即文件描述符)
5. 调用函数结束,取得一个文件描述符
当一个进程需要修改一个已经打开的文件时会经历如下步骤:
1. 进程提供 需要修改文件的 文件描述符 作为参数调用函数
2. 根据文件描述符在PCB中寻找到对应文件结构在文件表里的下标
3. 根据下标在文件表里取得对应的文件结构
4. 根据文件结构在inode缓冲队列里找到对应的inode
5. 根据inode的块指针修改磁盘上对应空间的数据
文件检索的关键 . 和 ..
任何一个目录下都需要两个子目录 . 和 ..
. 代表当前目录, .. 代表父目录,二者有助于文件系统的导航
具体的实现就是在当前目录下的目录项中将.和..添加进去
数据结构
/* 分区结构:一个分区就是一个文件系统 */
struct partition {
uint32_t start_lba; // 起始扇区
uint32_t sec_cnt; // 扇区数
struct disk* my_disk; // 分区所属的硬盘
struct list_elem part_tag; // 用于队列中的标记,用于将分区形成链表进行管理
char name[8]; // 分区名称
struct super_block* sb; // 本分区的超级块
struct bitmap block_bitmap; // 块位图
struct bitmap inode_bitmap; // inode位图
struct list open_inodes; // 本分区打开的inode缓冲队列
};
/* 超级块:文件系统元信息的配置文件 */
struct super_block {
uint32_t magic; // 用来标识文件系统类型,支持多文件系统的操作系统通过此标志来识别文件系统类型
uint32_t sec_cnt; // 本分区总共的扇区数
uint32_t inode_cnt; // 本分区中inode数量
uint32_t part_lba_base; // 本分区的起始lba地址
uint32_t block_bitmap_lba; // 块位图本身起始扇区地址
uint32_t block_bitmap_sects; // 扇区位图本身占用的扇区数量
uint32_t inode_bitmap_lba; // i结点位图起始扇区lba地址
uint32_t inode_bitmap_sects; // i结点位图占用的扇区数量
uint32_t inode_table_lba; // i结点表起始扇区lba地址
uint32_t inode_table_sects; // i结点表占用的扇区数量
uint32_t data_start_lba; // 数据区开始的第一个扇区号
uint32_t root_inode_no; // 根目录所在的I结点号
uint32_t dir_entry_size; // 目录项大小
uint8_t pad[460]; // 加上460字节,凑够512字节1扇区大小
} __attribute__ ((packed));
/* inode:文件的实质 */
struct inode {
uint32_t i_no; // inode编号
uint32_t i_size; //当此inode是普通文件时,i_size是指普通文件大小
//若此inode是目录,i_size是指该目录下所有目录项大小之和*/
uint32_t i_open_cnts; // 记录此文件被打开的次数
bool write_deny; // 写文件不能并行,进程写文件前检查此标识
uint32_t i_sectors[13]; // i_sectors[0-11]是直接块,
// i_sectors[12]用来存储一级间接块指针
struct list_elem inode_tag; //用于文件缓冲队列中
};
/* 文件结构 */
struct file
{
uint32_t fd_pos; // 记录当前文件操作的偏移地址,文件尾为-1
uint32_t fd_flag; // 文件操作标识符
struct inode *fd_inode;
};
/* 目录结构 */
struct dir {
struct inode* inode;
uint32_t dir_pos; // 记录在目录内的偏移
uint8_t dir_buf[512]; // 目录的数据缓存
};
/* 目录项结构 */
struct dir_entry {
char filename[MAX_FILE_NAME_LEN]; // 普通文件或目录名称
uint32_t i_no; // 普通文件或目录对应的inode编号
enum file_types f_type; // 文件类型
};
函数表
fs/fs.c
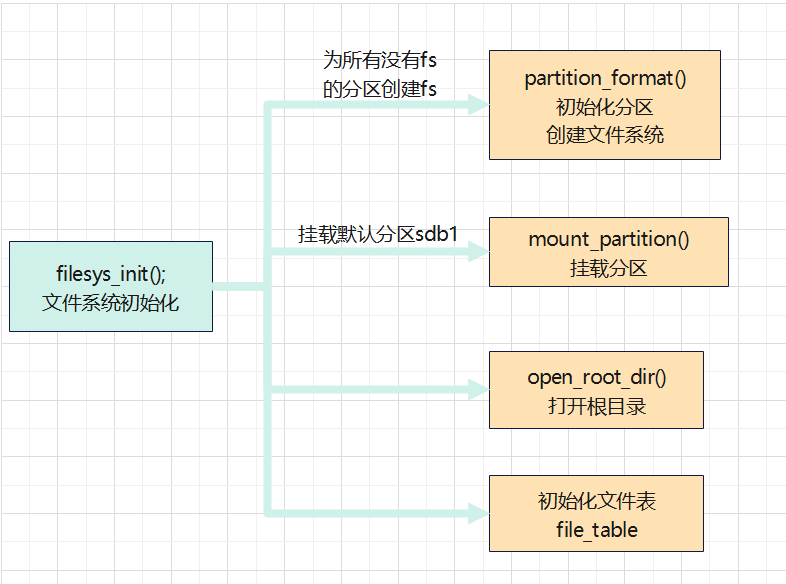
//------------------------文件系统初始化相关函数---------------------------------------
/*
@brief: 在磁盘上搜索文件系统,落没有则格式化分区创建文件系统
@detail:1.遍历整个磁盘,对每个已存在的分区创建文件系统
2.挂载默认分区
3.将当前分区的根目录打开
4.初始化文件表
@param: 无
@retval:无
*/
void filesys_init();
/*
@brief: 初始化part分区的元信息,创建文件系统
@detail:初始化超级块、空闲块位图、inode位图、inode数组、根目录并全部写入磁盘
@param: 略
@retval:无
*/
static void partition_format(struct partition* part);
/*
@brief: 挂载名为part_name(arg)的分区
@detail:将硬盘中的超级块、空闲块位图、inode位图全部读取到内存中
给cur_part赋值
@param: 略
@retval:无
*/
static bool mount_partition(struct list_elem *pelem, int arg);
//------------------------文件系统初始化相关函数---------------------------------------
//------------------------路径解析相关函数-----------------------
/*
@brief: 将最上层路径名称解析出来,存储到name_store,并返回子路径
@param: 略
@retval:无
*/
static char *path_parse(char *pathname, char *name_store);
/*
@brief: 返回路径深度
@param: 略
@retval:无
*/
int32_t path_depth_cnt(char *pathname);
/*
@brief: 搜索文件路径pathname,找到则返回其inode号,否则返回-1
@param: search_record:记录搜索过程中的父路径
@retval:无
@PS: 调用该函数后,会打开目标文件的父目录,并不会关闭,需要调用者关闭该目录
*/
static int search_file(const char *pathname, struct path_search_record *searched_record);
//------------------------路径解析相关函数-----------------------
//-------------------------系统调用-普通文件相关-------------------------
/*
@brief: 打开或创建普通文件
@detail: 1.先搜索该普通文件是否存在
2.存在则打开,不存在则创建并打开
@param: flags:文件操作标识符
@retval:成功后,返回文件描述符,否则返回-1
*/
int32_t sys_open(const char *pathname, uint8_t flags);
/*
@brief: 关闭文件描述符fd指向的文件
@detail: 1.调用file_close()关闭普通文件;
2.PCB->fd_table[fd]=-1;令文件描述符对应的数组可用
@param: flags:文件操作标识符
@retval:成功返回0,否则返回-1
*/
int32_t sys_close(int32_t fd)
/*
@brief: 将buf中连续count个字节写入文件描述符fd
@param: 略
@retval:成功则返回写入的字节数,失败返回-1
*/
int32_t sys_write(int32_t fd, const void *buf, uint32_t count);
/*
@brief: 从文件描述符fd指向的文件中读取count个字节到buf
@param: 略
@retval:若成功则返回读出的字节数,到文件尾则返回-1
*/
int32_t sys_read(int32_t fd, void *buf, uint32_t count);
/*
@brief: 重置用于文件读写操作的偏移指针(重置为:offset+文件指针位置)
@param: whence:文件指针位置标识符
offset:相对于文件指针位置的偏移量
@retval:成功时返回新的偏移量,出错时返回-1
*/
int32_t sys_lseek(int32_t fd, int32_t offset, uint8_t whence);
/*
@brief: 删除普通文件(普通文件已打开则删除失败)
@param: 略
@retval:成功返回0,失败返回-1
*/
int32_t sys_unlink(const char *pathname);
//-------------------------系统调用-普通文件相关-------------------------
//-------------------------系统调用-目录文件相关-------------------------
/*
@brief: 创建目录文件(并不打开)
@detail:1.申请inode位图,并同步到磁盘
2.申请block位图,并同步到磁盘(先分配一个块就够用)
3.往inode指向的数据块写入目录项'.'和'..'
4.要将本目录的inode初始化,并同步到磁盘(无需申请内存空间)
5.将关于本目录的目录项写入父目录数据块(写入磁盘)
6.父目录inode更新大小并同步到磁盘
@param: pathname:目录文件路径
@retval:成功返回0,失败返回-1
*/
int32_t sys_mkdir(const char *pathname);
/*
@brief: 打开目录文件,并返回目录指针
@detail:调用dir_open()来打开目录
(目录打开只涉及part->open_inodes不涉及文件表、文件描述符数组等)
@param: 略
@retval:成功返回目录指针,失败返回-1
*/
struct dir *sys_opendir(const char *name);
/*
@brief: 关闭目录
@detail:调用dir_close()来关闭目录
@param: 略
@retval:成功返回0,失败返回-1
*/
int32_t sys_closedir(struct dir *dir);
/*
@brief: 根据dir当前偏移位置,读取一个目录项,并更新偏移位置(调用dir_read()实现)
@param: 略
@retval:成功后返回其目录项地址,到目录尾时或出错时返回NULL
*/
struct dir_entry *sys_readdir(struct dir *dir);
/*
@brief: 把目录dir的指针dir_pos置0
@param: 略
@retval:无
*/
void sys_rewinddir(struct dir *dir);
/*
@brief: 删除空目录(调用dir_remove()实现)
@param: 略
@retval:成功时返回0,失败时返回-1
*/
int32_t sys_rmdir(const char *pathname);
//-------------------------系统调用-目录文件相关-------------------------
//-------------------------系统调用-cwd相关-------------------------
/*
@brief: 获得父目录的inode编号(利用目录项目'..')
@param: 略
@retval:无
*/
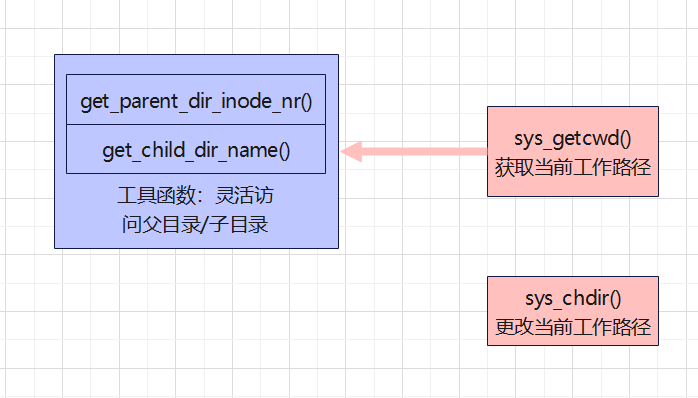
static uint32_t get_parent_dir_inode_nr(uint32_t child_inode_nr, void *io_buf);
/*
@brief: 在inode编号为p_inode_nr的目录中查找inode编号为c_inode_nr的子目录的名字,将名字存入缓冲区path.
@param: 略
@retval:成功返回0,失败返-1
*/
static int get_child_dir_name(uint32_t p_inode_nr, uint32_t c_inode_nr, char *path, void *io_buf);
/*
@brief: 把当前工作目录绝对路径写入buf, size是buf的大小.
@detail:根据PCB->cwd_inode_nr一层层向上追溯求得当前工作目录路径
@param: 略
@retval:成功返回buf,失败返NULL
*/
char *sys_getcwd(char *buf, uint32_t size);
/*
@brief: 更改当前工作目录为绝对路径path
@detail:实质是修改PCB->cwd_inode_nr
@param: 略
@retval:成功则返回0,失败返回-1
*/
int32_t sys_chdir(const char *path);
//-------------------------系统调用-cwd相关-------------------------
//-------------------------系统调用-文件属性相关-------------------------
/*
@brief: 在buf中填充文件结构相关信息
@param: 略
@retval:成功时返回0,失败返回-1
*/
int32_t sys_stat(const char *path, struct stat *buf);
//-------------------------系统调用-文件属性相关-------------------------
//------------------------转换函数----------------------
/*
@brief: 将文件描述符转化为文件表的下标
@param: 略
@retval:无
*/
static uint32_t fd_local2global(uint32_t local_fd);
//------------------------转换函数----------------------
fs/dir.c
/*
@brief: 打开根目录
@detail:1.利用inode_open()打开根目录
2.并给root_dir赋值
@param: 略
@retval:无
*/
void open_root_dir(struct partition *part);
/*
@brief: 在分区part上打开节点号为inode_no的目录并返回目录指针
@detail:1.利用inode_open()打开目录文件
2.给目录结构pdir申请空间,初始化并返回
(目录打开只涉及part->open_inodes不涉及文件表、文件描述符数组等)
@param: 略
@retval:无
*/
struct dir *dir_open(struct partition *part, uint32_t inode_no);
/*
@brief: 关闭目录
@detaili:1.利用inode_close()关闭目录,根目录不能被关闭
2.释放目录结构dir的空间
@param: 略
@retval:无
*/
void dir_close(struct dir *dir);
/*
@brief: 在目录中寻找指定目录项
@detail:在part分区内的pdir目录内寻找包含name文件或目录的目录项
@param: 略
@retval:找到后返回true并将其目录项存入dir_e,否则返回false
*/
bool search_dir_entry(struct partition *part, struct dir *pdir, const char *name, struct dir_entry *dir_e);
/*
@brief: 在内存中初始化目录项p_de
@param: 略
@retval:无
*/
void create_dir_entry(char *filename, uint32_t inode_no, uint8_t file_type, struct dir_entry *p_de);
/*
@brief: 将目录项p_de写入父目录parent_dir中(直接写入磁盘)
@param: io_buf:主调函数提供的缓冲区
@retval: 成功返回true,失败返回false
@PS: 父目录的inode.size更改过了,但并没有同步到磁盘的inode_table里!!
调用者要负责把父目录的inode同步到磁盘
*/
bool sync_dir_entry(struct dir *parent_dir, struct dir_entry *p_de, void *io_buf);
/*
@brief: 把分区part目录pdir中关于inode_no的目录项删除(会将更新过的父目录inode写入磁盘)
@param: 略
@retval:成功返回true,失败返回false
*/
bool delete_dir_entry(struct partition *part, struct dir *pdir, uint32_t inode_no, void *io_buf);
/*
@brief: 根据dir当前偏移位置,读取一个目录项,并更新偏移位置
@param: 略
@retval:成功返回目录项,失败返回NULL
*/
struct dir_entry *dir_read(struct dir *dir);
/*
@brief: 判断目录是否为空
@detail:目录为空则代表目录中只含有.和..两个目录项
@param: 略
@retval:空返回true,非空返回false
*/
bool dir_is_empty(struct dir *dir);
/*
@brief: 移除目录child_dir
@detail:1.调用delete_dir_entry在父目录中移除本目录的目录项
2.调用inode_release()回收本目录的inode
@param: 略
@retval:成功返回目录项,失败返回NULL
*/
int32_t dir_remove(struct dir *parent_dir, struct dir *child_dir);
fs/inode.c
/*
@brief: 打开并返回part分区里目标inode节点
两个重要的功能:一个是打开inode、一个是返回inode节点
@detail:1.现在inode缓冲区队列中寻找该inode,若已打开则增加inode->i_open_cnts并返回inode
2.没找到就去磁盘中寻找该inode读取到内存里,并放到inode缓冲区队列,返回inode
@param: part:目标分区
inode_no:要打开的inode节点的i_no号
@retval:无
*/
struct inode *inode_open(struct partition *part, uint32_t inode_no);
/*
@brief: 关闭inode
@detail:1.减少inode->i_open_cnts
2.inode->i_pen_cnts减少后若为0,则将从inode缓冲队列里去除,并释放为inode分配的空间
@param: 略
@retval:无
*/
void inode_close(struct inode *inode)
/*
@brief: 初始化new_inode,为其赋值
@param: 略
@retval:无
*/
void inode_init(uint32_t inode_no, struct inode *new_inode)
/*
@brief: 定位inode在扇区的位置
@detail:在part里获取inode所在的扇区和扇区内的偏移量并存到inode_pos中
@param: 略
@retval:无
*/
static void inode_locate(struct partition *part, uint32_t inode_no, struct inode_position *inode_pos);
/*
@brief: 将inode写入到磁盘的分区part中
@param: 略
@retval:无
*/
void inode_sync(struct partition *part, struct inode *inode, void *io_buf);
/*
@brief: 回收inode
@detail:1.回收分配给inode的所有block(修改block_bitmap)
2.回收inode(修改inode_bitmap)
3.调用inode_delete删除硬盘上的inode数据(可以不用这步)
4.确保该inode完全关闭
@param: 略
@retval:无
*/
void inode_release(struct partition *part, uint32_t inode_no);
/*
@brief: 将硬盘分区part上的对应的inode清除(修改磁盘上的inode_table)
@param: inode_no:要清楚的inode号
@retval:无
*/
void inode_delete(struct partition *part, uint32_t inode_no, void *io_buf);
fs/file.c
//------------------------文件表 文件描述符数组 相关操作-----------------------
/*
@brief: 从文件表file_table中获取一个空闲位
@param: 无
@retval:成功返回文件表下标,失败返回-1
@PS:如果file_table[fd_idx].fd_inode == NULL,则判断文件结构可用
*/
int32_t get_free_slot_in_global(void);
/*
@brief: 将全局描述符(文件表下标)安装到进程或线程自己的文件描述符数组fd_table中
@param: globa_fd_idx:文件表的下标(全局文件描述符)
@retval:成功返回文件描述符(文件描述符数组的下标),失败返回-1
*/
int32_t pcb_fd_install(int32_t globa_fd_idx);
//------------------------文件表 文件描述符数组 相关操作-----------------------
//---------------------------位图操作-------------------------
/*
@brief: 从inode位图里分配一个inode结点 (内存操作)
@param: 略
@retval:返回节点号i_no(就是inode在位图中的位置)
*/
int32_t inode_bitmap_alloc(struct partition *part);
/*
@brief: 从block位图里分配1个空闲块(1扇区),返回其扇区地址(内存操作)
@param: 略
@retval:略
*/
int32_t block_bitmap_alloc(struct partition *part);
/*
@brief: 同步内存里的位图结构到磁盘上
@detail:将内存中bitmap第bit_idx位所在的512字节同步到硬盘
@param: btmp_type:标识是inode位图还是block位图
@retval:略
*/
void bitmap_sync(struct partition *part, uint32_t bit_idx, uint8_t btmp_type);
//---------------------------位图操作-------------------------
//-------------------------------普通文件相关操作--------------------------------
/*
@brief: 创建并打开普通文件(磁盘操作)
@detail:1.创建new_inode(修改inode位图、inode分配内存、inode初始化)
2.修改父目录(对应目录项写入父目录(写入磁盘),修改父目录inode.size)
3.同步 父目录inode、new_inode、inode位图
4.打开该文件(添加到file_table、PCB中的fd_table、Part中的open_inodes)
@param: flag:文件操作标识符
@retval:成功则返回文件描述符,否则返回-1
*/
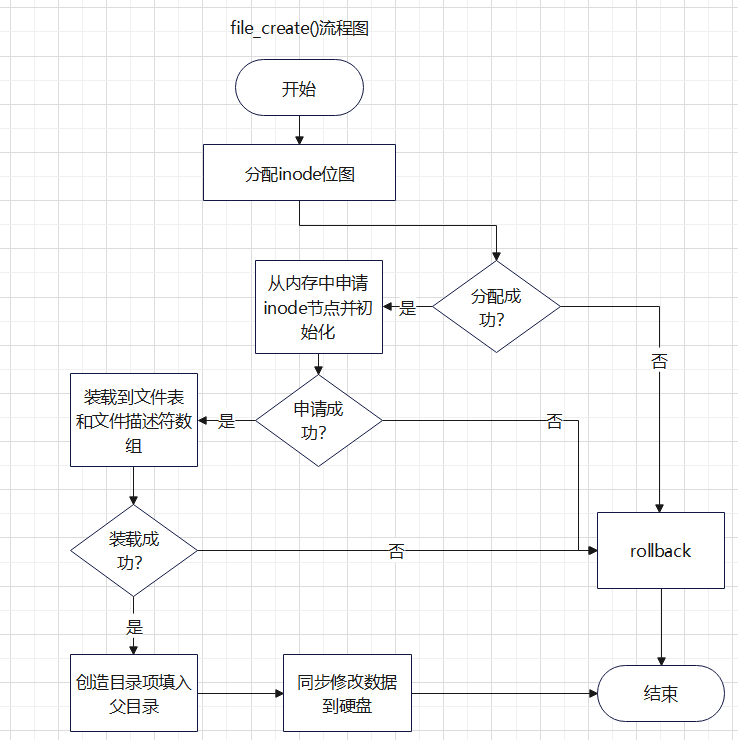
int32_t file_create(struct dir *parent_dir, char *filename, uint8_t flag);
/*
@brief: 打开编号为inode_no的inode对应的普通文件
@detail:1.修改file_table
2.修改PCB->fd_table
3.调用inode_open()修改part->open_inodes
@param: 略
@retval:成功则返回文件描述符,否则返回-1
*/
int32_t file_open(uint32_t inode_no, uint8_t flag);
/*
@brief: 关闭文件结构
@detail:1.调用inode_close()修改part->open_inodes
2. file->fd_inode = NULL; 使文件结构可用
@param: file:要关闭的文件结构
@retval:失败返回-1,成功返回0
@PS:没有将PCB中的文件描述符数组对应位置-1!!!
调用者要负责将PCB->fd_table[]置-1
*/
int32_t file_close(struct file *file);
/*
@brief: 把buf中的count个字节写入file
@param: 略
@retval:成功则返回写入的字节数,失败则返回-1
*/
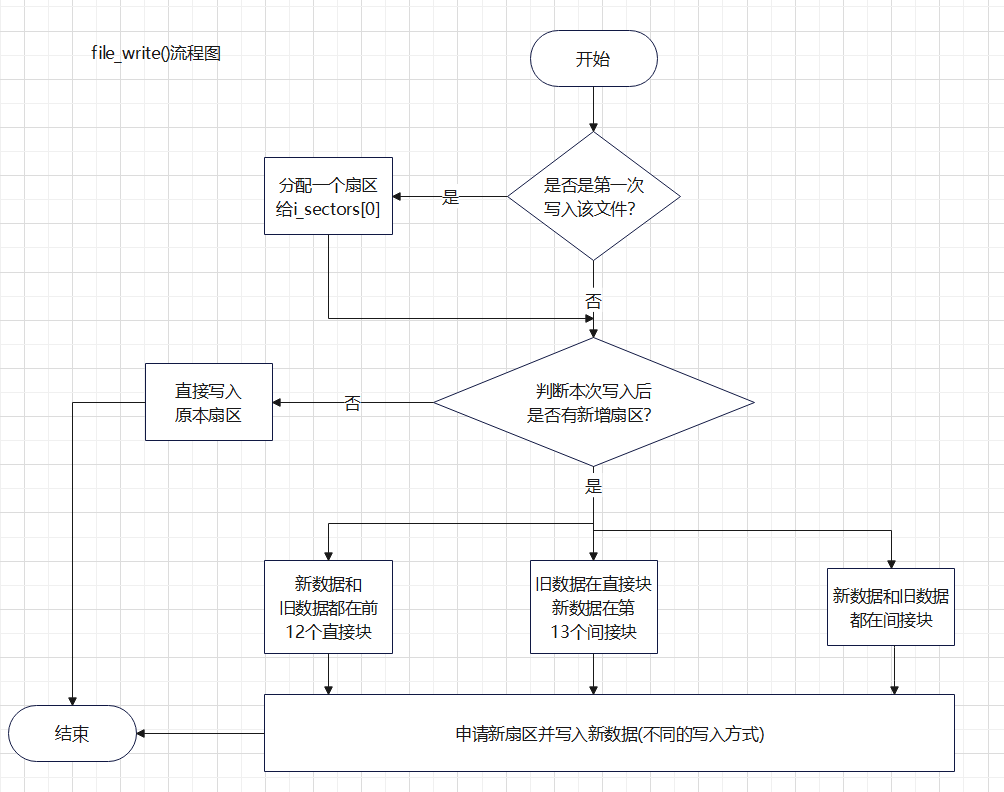
int32_t file_write(struct file *file, const void *buf, uint32_t count);
/*
@brief: 从文件file中读取count个字节写入buf
@param: 略
@retval:返回读出的字节数,若到文件尾则返回-1
*/
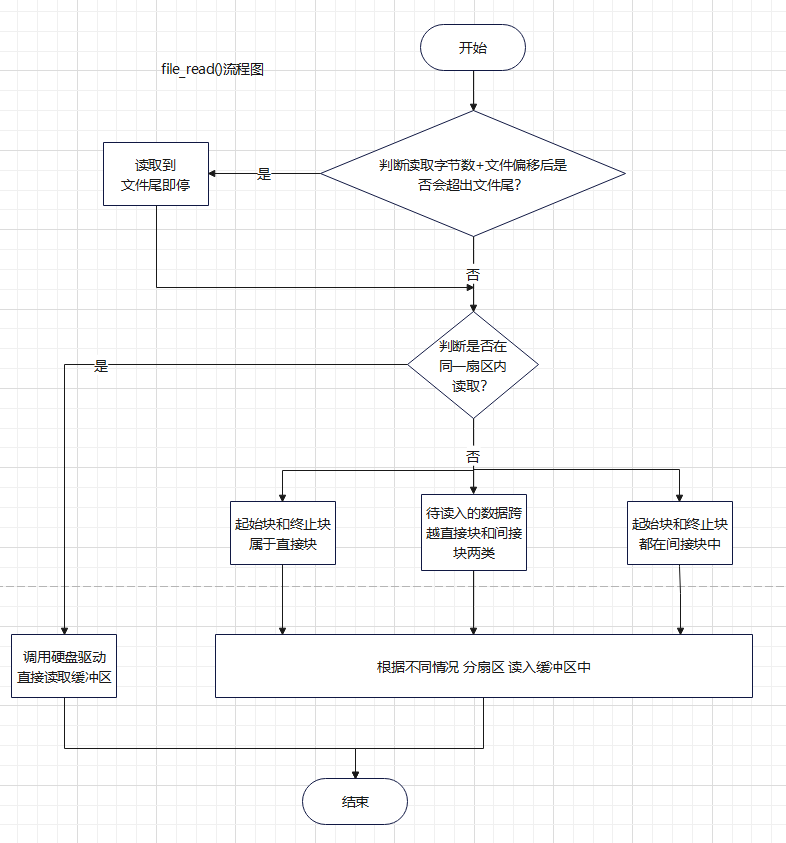
int32_t file_read(struct file *file, void *buf, uint32_t count);
//-------------------------------普通文件相关操作--------------------------------
关键函数说明
文件系统初始化函数
文件操作相关函数
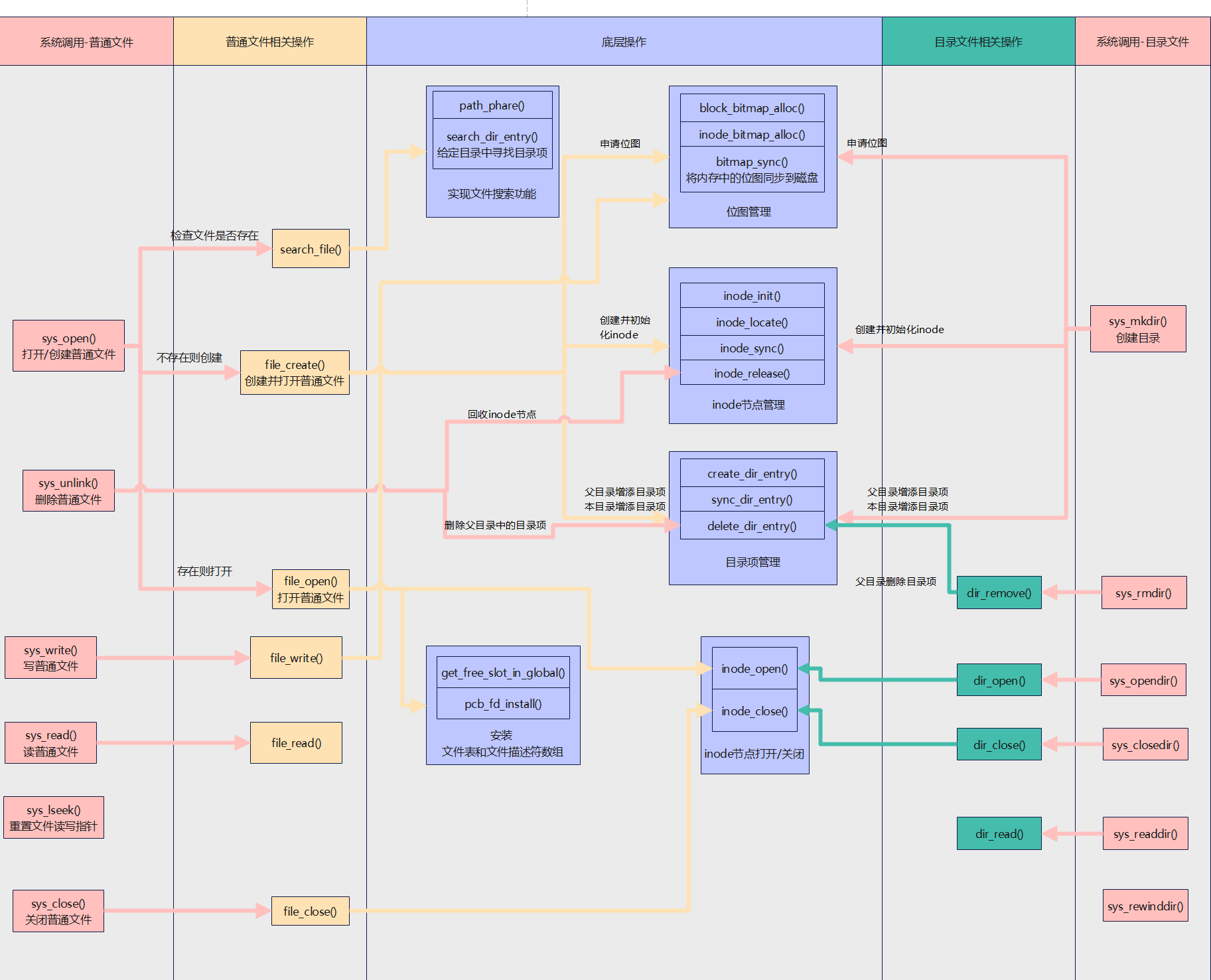
工作路径相关函数
fs/file.c/file_create()
fs/file.c/file_write()
fs/file.c/file_read()