SimpleOS-Boot引导
整体设计方案
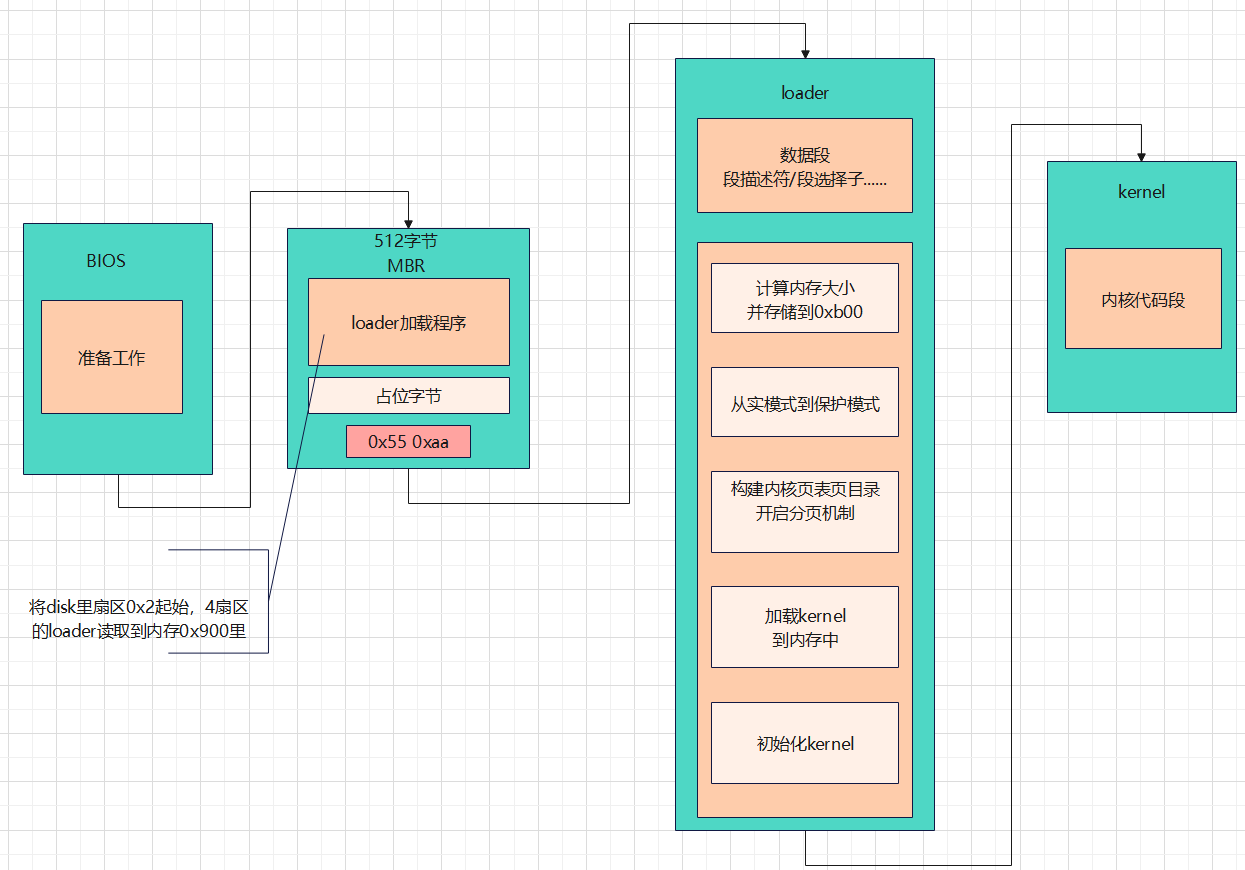
如图电脑的启动后接力棒的第一棒从BIOS开始,第二棒MBR负责把硬盘上的loader加载到内存里,第三棒loader处理完5个子功能后把接力棒正式交给内核。
我们在本模块所做的事,就是构建具备上述功能的MBR以及loader。
在了解MBR和loader的设计之前请先了解实模式下低端物理内存1MB的布局
MBR设计
MBR只需要负责加载loader到相应位置即可
MBR的程序代码分为三个部分:
寄存器初始化(包括栈顶指针初始化)
调用函数loader_ready_proc()(寄存器传参)
PS:请先了解LBA28相关知识
loader_ready_proc()的具体实现(功能是装载loader,也就是把loader写入磁盘相应位置)
PS:请先了解磁盘写入相关知识
保证MBR一共512字节,并最后两字节必须是0x55和0xaa,使得BIOS能够检测并识别
loader设计
loader要负责做的事情可多了,大致可分为六个部分
数据段
loader程序的数据段里存放着GDT等重要数据结构,安排如下图所示

计算内存大小并存储到0xb00(也就是total_men_bytes标号处)
我们模仿Linux获取内存的方法,调用BIOS中断0x15的三个子功能(0xe820、0xe801、0x88)去获取内存(一种失败了就接着使用另外一种,直到成功)
0xb00则是我们安排在loader.S数据段的一个固定位置,当然如果你喜欢也可以存放在其他位置。
注意:我们使用BIOS中断0x15时,该中断会以ARDS数据结构(描述内存段大小的信息)的形式,返回数个ARDS,所以我们需要在loader.S中划分一块缓冲区用于临时存放返回的ARDS
从实模式切换到保护模式
PS:请先了解保护模式相关知识点,以及如何从实模式进入保护模式
构建内核页表页目录,开启分页机制
PS:请先了解分页机制
我们所要建立的满足可以自举证的分页模型如下图所示
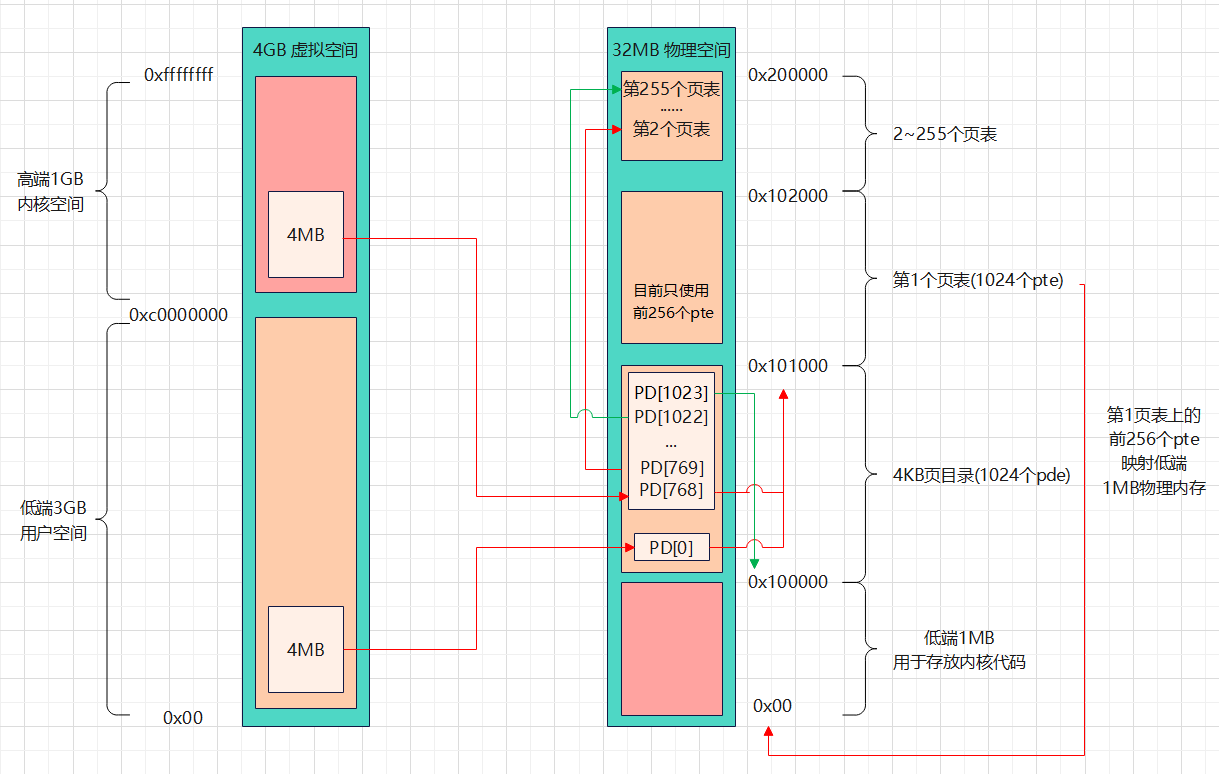
物理空间中低端1MB用于存放内核代码,紧接着0x100000~0x200000这1MB空间用于存放255个页表+1个页目录,每个页表/页目录都刚好是一个4KB自然页大小,每个页表项/页目录项则占4字节大小
虚拟空间
0x00~0x100000和0xc0000000~0xc0100000两个区间都被映射到物理空间的低端1MB内核代码区间PD[1023]指向页目录本身,为的是实现在开启分页机制后还能正确访问页表和页目录
如果虚地址高10位全为1、虚地址中10位全为0,就把PD[0]当成自己的页表项,最终指向物理页地址0x101000
如果虚地址高10位全为1、虚地址中10位全为1,就把PD[1023]当成自己的页表项,最终指向物理页地址0x100000
如果虚地址高10位全为1、虚地址中10位处于一定范围内,就把PD[768]~PD[1022]当成自己的页表项目,最终指向物理地址0x101000及以上空间总结出不变的规律:
- 要获取页目录表物理地址:让虚位高20位地址全为1,低12位全为0,即0xfffff000。这就是页目录自身的起始物理地址
- 要访问页目录中的页目录项,即获取页表物理地址:使虚拟地址为0xfffffxxx,其中xxx是页目录项的索引*4
- 访问页表中的页表项:虚拟地址公式为 0x3ff<<22+中间10位<<12+低12位(中间10位是页表的索引,低12位为页表内的偏移地址)
加载kernel到内存中
将硬盘从0x9开始占据200扇区的kernel代码读取到内存0x70000起始处
初始化kernel
PS:请先了解加载并初始化内核相关知识以及elf文件格式
数据结构
无
函数表
boot/mbr.S
/* @brief: 该函数负责把磁盘上的loader装载到内存里(汇编函数/寄存器传参) @param: loader_start_sector是loader的LBA28扇区地址 loader_base_addr是内存起始地址 sector_cnt是移动的扇区数目 @retval:无 */ void loader_ready_proc(loader_start_sector,loader_base_addr,sector_cnt);boot/loader.S
/* @brief: 该函数负责5件事分布如下:(汇编函数) 1. 计算内存并存储到0xb00 2. 从实模式到保护模式 3. 构建内核页表页目录,开启分页机制 4. 加载kernel到内核中 5. 初始化kernel @param: 无 @retval:无 */ void loader_start();
关键函数说明
无
背景知识/工具图表
实模式下低端物理内存1MB布局
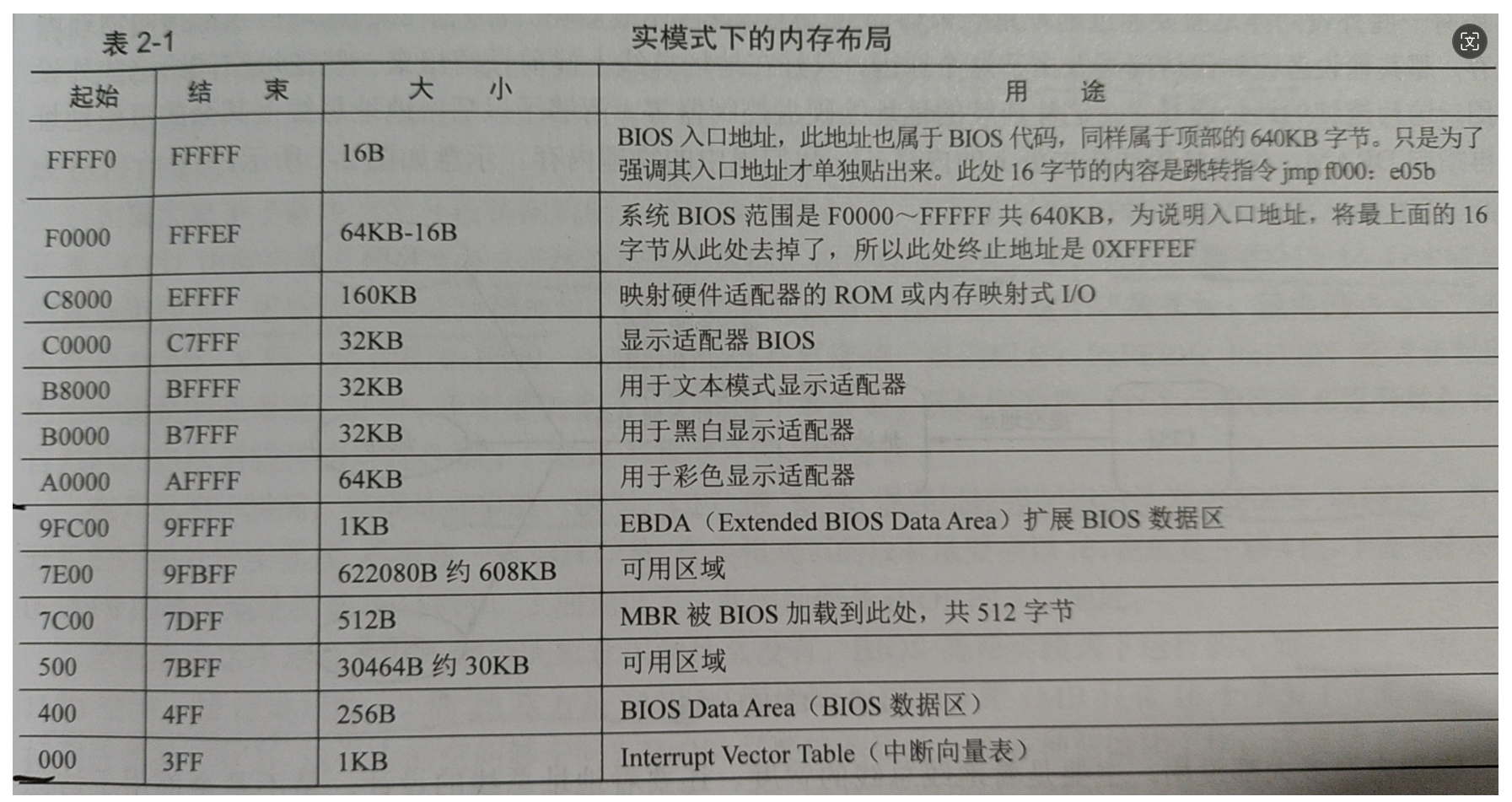
我们整个SimpleOS的代码实际上只会装载到
0x500~0x9FBFF这块内存区间(包括两块空闲的可用区域,和一块由BIOS确定的MBR区域)512字节的MBR将会被BIOS强制装载到
0x7C00~0x7DFF,(MBR只负责加载loader,运行过一次就没用了,之后可以被其他代码覆盖)2048字节的loader规划在可用区间
0x900~0x1100(loader是内核的起点,安排在离0x500近一点的地方,为之后的内核文件腾出足够的空间。至于和0x500之间存在的一点间隔存储个人决策,可以忽略)200扇区kernel.bin,将其装载在
0x70000~0x89000可用区域,(内核代码应该装载在可用空间的尽可能高位,为内核映像文件腾出位置)保护模式下一些虚地址分配
0xc0001500(虚地址)作为内核代码的入口
一般来说可用空间的上界限0xc009fc00是最好的栈顶,但是为了让内存的每一块都形成4KB的自然页,所以栈顶最好取4KB的整数倍,因此栈顶设置为
0xc009f0000xc009e000~0xc009f0004KB空间分配给内核主线程PCB0xc009a000~0xc009e000这四个页的空间(可管理一共512MB空间)大小全给位图(物理内核内存池位图、物理用户内存池位图、虚拟内核内存池位图)
LBA28相关知识
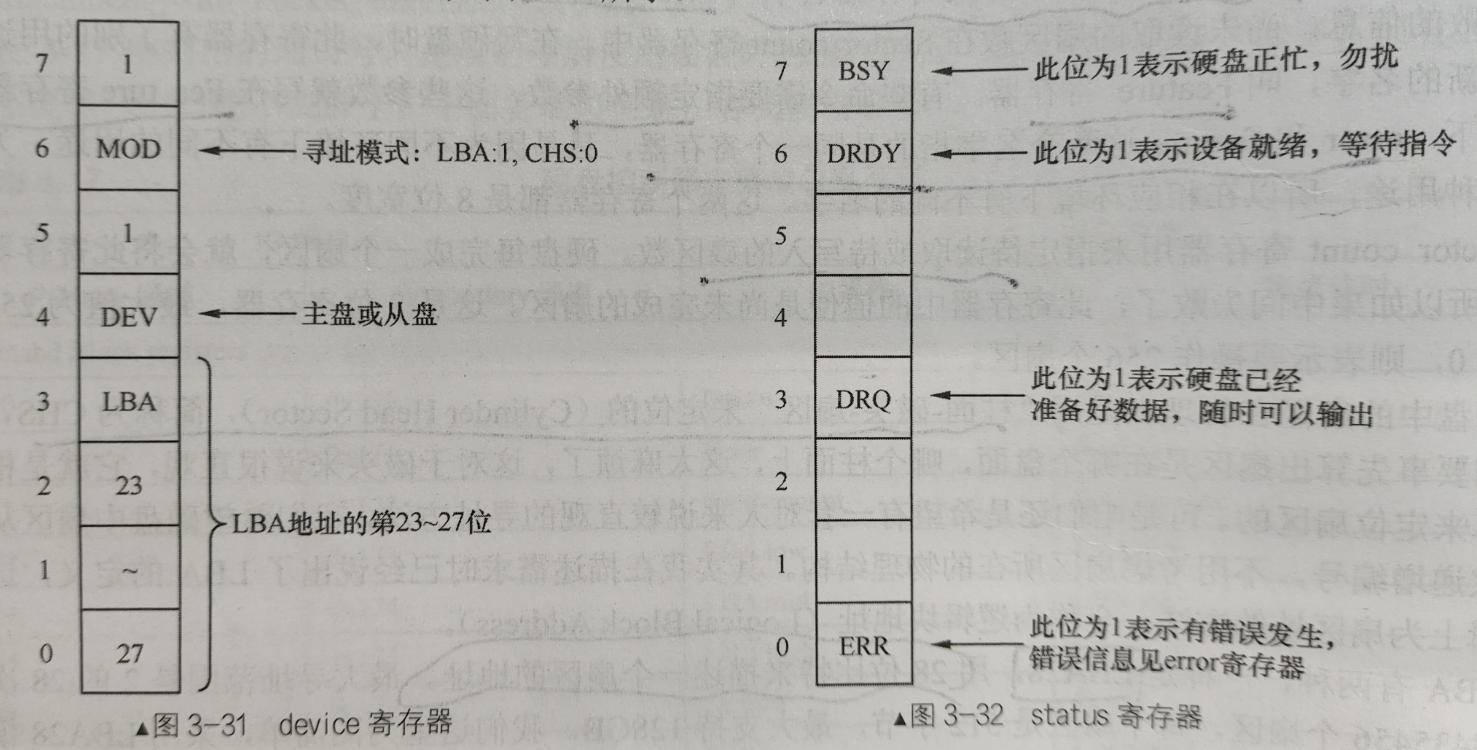
LBA28是用28位比特来描述一个扇区的地址的一种方式
其中前24位分别写在3个8位寄存器LBAlow、LBAmid、LBAhigh,最后4位写在device寄存器里
磁盘写入相关知识
硬盘并行接口-PATA
PATA接口的线缆也称IDE线
一个主盘提供了两个IDE插槽,这两个插槽称为两个通道,IDE0叫Primary通道,IDE1叫Secondary通道
每一个IDE线都可以挂载两块硬盘,一个主盘(master),一个从盘(slave)
硬盘操作方法
当我们要读取硬盘时,我们要先在控制寄存器里写入 读取命令字,然后才能从相关寄存器里读取到所需要的数据
而当我们需要写入硬盘时,我们要先在相关寄存器里写入数据,然后再向控制寄存器里写入 写入命令字,即完成写入
硬盘控制器主要的端口寄存器
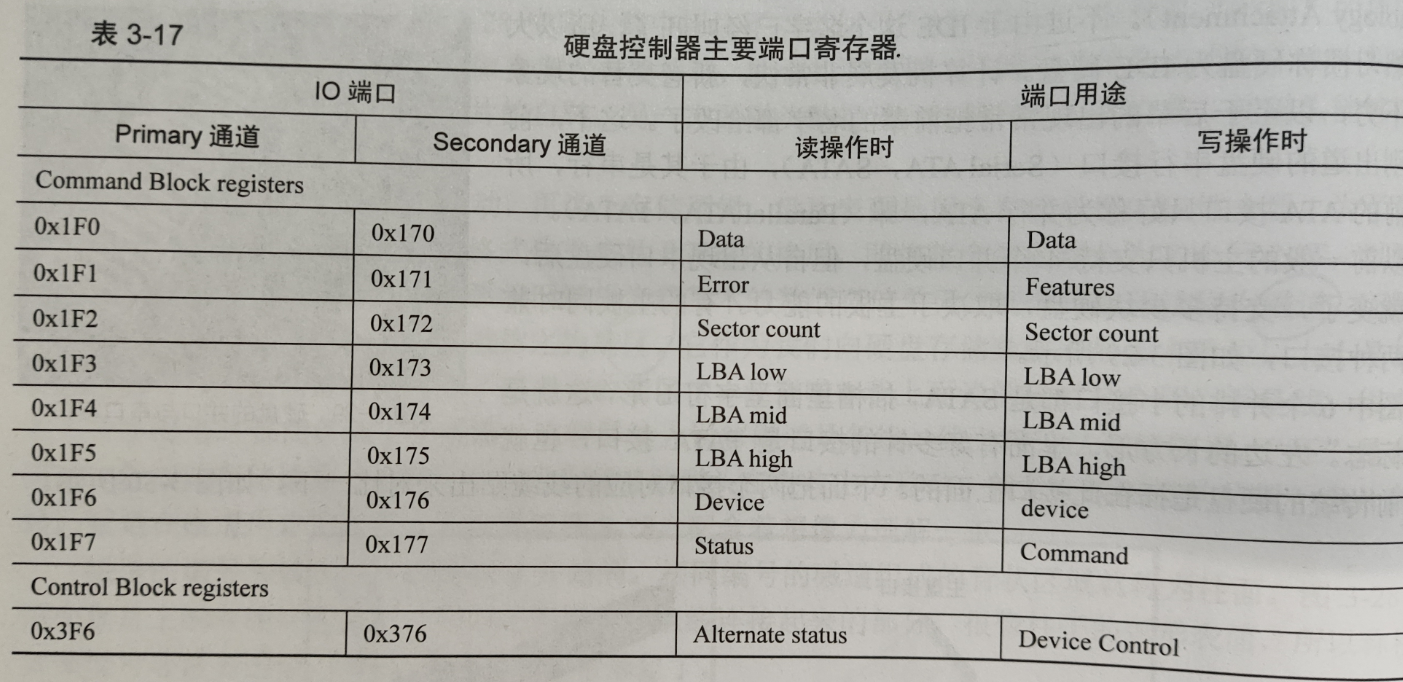
Command Block registers用于向硬盘驱动器写入命令字或者从硬盘控制器里活得硬盘状态
Control Block registers用于控制硬盘状态
data寄存器用于管理数据
Error寄存器用于记录失败时的错误信息/Feature寄存器用于部分命令需要指定额外参数
Sector count寄存器用来指定带读取/写入的扇区数目
3个8位的LBA寄存器用于记录LBA28地址的低24位(高4位记录在device寄存器)
Command寄存器用于写入操作时存放命令字,可使用命令字如下:
identify:0xEC (硬盘识别)
read sector:0x20 (读扇区)
write sector:0x30(写扇区)device寄存器是杂项,status寄存器用于给出硬盘状态信息,具体信息见下图
与端口交互的in/out指令
in指令用于从端口中读取数据,格式如下:
in al,dx in ax,dx只要使用in指令,源操作数必须是dx(存放端口号),而目的操作数是用al,还是ax取决于dx端口指代的寄存器是8位宽还是16位宽
out 指令用于往端口中写数据,格式如下:
out dx,al out dx,ax out 立即数,al out 立即数,axout指令的源操作数是ax还是al取决于目标端口指代的寄存器是8位宽还是16位宽,源操作数可以是立即数直接给出端口号,也可以用dx(存放端口号)
硬盘操作约定顺序
- 先选择通道,往该通道的sector cout寄存器写入待操作的扇区数
- 往通道上的三个LBA写入扇区地址LBA28的低24位
- 往device写入LBA28的高4位,指定主从盘,并选择LBA寻址模式
- 第四步往该通道的command寄存器写入命令(一旦写入立即执行)
- 读取status寄存器,判断硬盘工作是否完成
- 将硬盘数据读出(如果是写硬盘则无需这步)
保护模式概述
为什么要有保护模式(实模式的缺点)
实模式下用户程序和操作系统同一等级,而且逻辑地址就是物理地址,用户程序可以随意修改段基址访问所有内存,不安全
实模式16位寄存器决定访问超过64KB的内存区域要切换段基址、麻烦
一次只能运行一个程序,无法充分利用计算机资源
只有20条地址线,最大可用内存的寻址范围只有1MB,不够用
保护模式的特点
应用程序只能访问虚拟地址,虚拟地址由处理器和操作系统协作转换后才显示真正的物理地址
保护模式的运行环境是32位,寄存器、数据线、地址线也相应都被扩展到32位,指令格式也有了相应的扩展(允许32位源操作数)
保护模式不再使用中断向量表、段基址寄存器这些概念。取而代之的是段选择子寄存器、全局描述符、中断描述符表、各种门结构
保护模式引入了特权级的概念,应用程序不再和操作系统拥有同一特权级
保护模式的扩展
寄存器扩展:

保护模式下寄存器、地址线和数据总线都扩展到32位,内存寻址空间可达4GB,段内寻址空间也可达4GB。也就是说对内存的访问甚至可以让段基址=0,只由一个记录偏移量的寄存器来访问内存,这也就是所谓的平坦模型
另外一提:保护模式抛弃基址这个概念,而是在内存里放入一个全局描述符表,每一个表项都是一个段描述符,用来描述各个内存段的起始地址、大小、权限等信息。段寄存器保护的也不再是段基址了,而是“选择子”,选择子本质上就是全局描述符表中的索引,就像是数组下标一样的东西。
寻址扩展:

如图所示保护模式的寻址方式更加灵活多变,不仅在基址寄存器(所有通用寄存器都可)和变址寄存器(处理esp外的所有通用寄存器都可)有了更多选择外,还引入了比例因子
运行模式反转:
由于32位CPU兼容保护模式和实模式,所以如果你在保护模式下使用实模式的命令,或者在实模式下使用保护模式的命令,都会触发运行模式反转,将会在二进制机器码前加上相应的反转前缀。
注意:模式反转前缀只对单条指令有效,效果并非是全局的
[bit 16] ;告诉编译器接下来的代码是实模式 [bit 32] ;告诉编译器接下来的代码是保护模式操作数反转前缀 0x66

如图上半部分是代码,下半部分是编译后的机器指令
第三行在[bit 16]实模式下使用了eax,触发了保护模式转换,因此机器码前加了前缀0x66
第五行在[bit 32]保护模式下使用了ax,触发了实模式转换,因此机器码前加了前缀0x66
寻址方式反转前缀 0x67
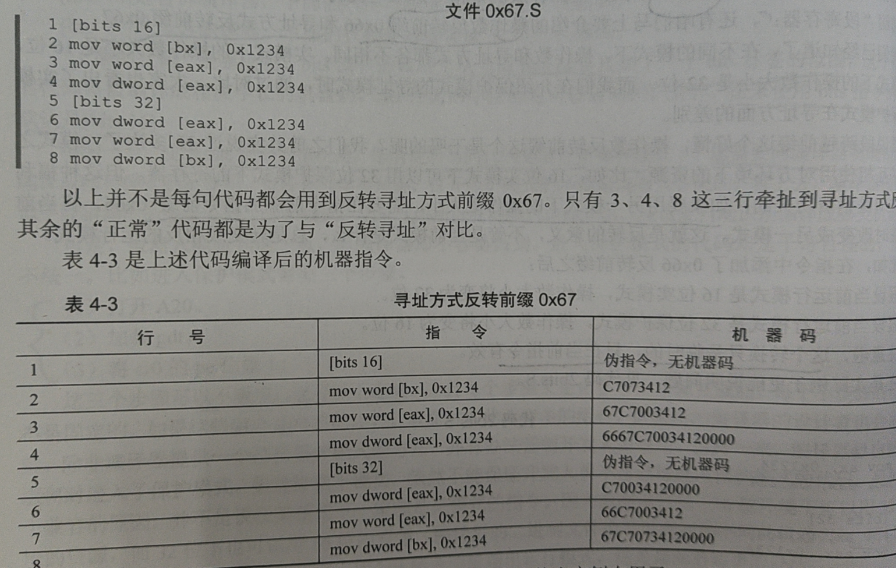
第四行在[bit 16]实模式下同时使用了保护模式的32位源操作数和更加灵活的寻址方式,触发模式转换,机器码添加了前缀0x66、0x67
指令扩展
指令扩展后允许32位寄存器和32位源操作数
从实模式到保护模式
从实模式到保护模式我们要执行四个步骤:
打开A20地址线
加载GDT
将CR0的PE位置1
使用jump指令更新流水线,避免指令出错
对于这三个步骤的讲解请看下文
段描述符
到了保护模式下,内存段不再是简单用寄存器加载即可用,而是需要提前把段定义好才可使用。全局描述符就是用来存储对每个段描述的表,全局描述符中的每一个表项包含段描述符,段描述符就是对一个段的描述,64位段描述符格式如下:

段基址:
每个段都有32位的段基址,在段描述符中被拆分成三块存储。
为什么被拆分成三块?为的是兼容,实模式下段基址是16位,80286有关短暂的24位段基址,而现在则是32位段基址,为了兼容原本应该连续存放的段基址被拆分为16-8-8的形式。
当需要查看段基址时,硬件会把三个分散的段基址取出来并拼接在一起得到一个完整的32位段基址。
PS:现在知道为什么有那么多屎山代码了,为了兼容旧时代的程序,屎山代码将成为每一个持续发展产品的最终归宿!
段界限:
段界限表示段边界的扩展最值,20位段界限被拆分为两部分(当然又是为了兼容)。
段界限是一个单位量,单位要么是1字节,要么是4KB(单位由G段决定)。也就是说段的最大寻址范围要么是1*2^20=1MB;要么是2*12*2^20=4GB。(注意寻址范围!=空间)
实际的段界限边界值=(描述符中段界限+1)*(段界限的粒度大小:4KB/1Byte)-1
S字段和type字段:
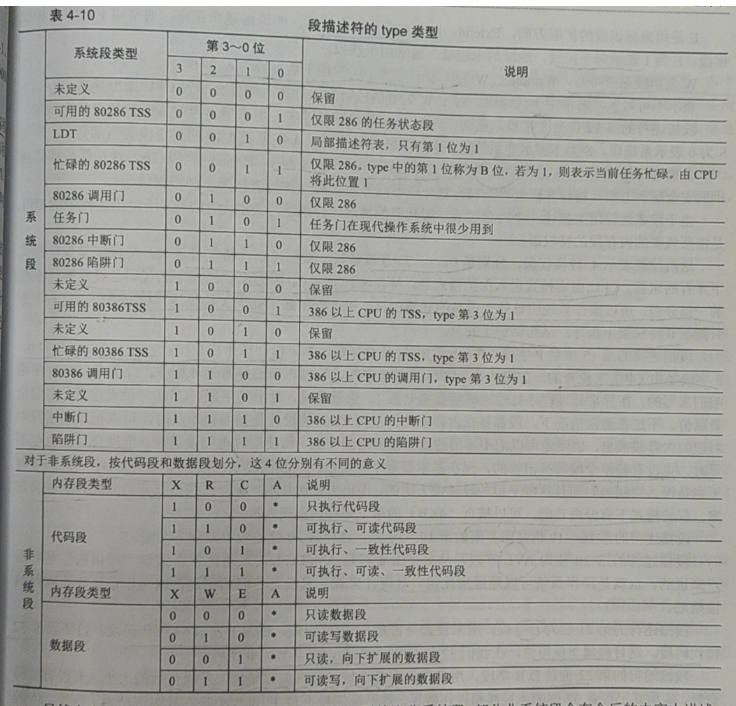
S字段只有1位:S=0 则说明是系统段(凡是硬件允许需要用到的东西,程序入口、调用门之类);S=1 则说明是非系统段(凡是软件运行需要的东西,数据、代码、栈都是数据段)
type字段有4位:type字段只有在S确认后才有意义,X区分代码段和数据段,R代表是否可读,W代表是否可写,C代表是否一致,E代表向上扩展(E=0,低地址到高地址)或向下扩展(E=1,高地址到低地址),A代表是否被CPU读过(CPU访问过则置1)
DPL(Descriptor Privilege Level)
2位的DPL字段表示特权级,特权级从0~3,数字越低特权级越高,操作系统是0级,一般应用程序是3级
P字段(Present):
1位P表示段是否存在,有时候内存不够时,保护模式下CPU可能会按页(4KB)的单位将内存换到磁盘里,此时相当于该段不存在,即P=0;
AVL字段(Avaliable):
1位AVL字段代表该段是否可用,是否可用是对用户来说,对操作系统来说可随意访问此位
L字段:
1位L字段,L=1表示代码段是64位,L=0表示代码段是32位,我们在32位地址下编程将其设置为0即可
D/B字段:
1位D/B字段指定有效地址及操作数大小,对不同段的意义不同
如果针对代码段,D=0时指令中有效地址和操作数是16位,指令有效地址用IP寄存器;D=1时指令中有效地址和操作数是32位,指令有效地址用EIP寄存器
如果针对栈段,B=0时栈使用SP寄存器,栈最大寻址范围为2^16;B=1时栈使用ESP寄存器,栈最大寻址范围为2^32
G段:
1位G段用来指定段界限的单位大小,G=0时,段界限的单位时1字节;G=1时,段界限的单位是4KB
全局描述符号GDT、选择子以及GDTR寄存器
GDT(Global Descriptor Table)相当于是段描述符的数组,每一表项都是一个段描述符
选择子是什么?选择子由三部分组成,如下图:

0~1位用来存储RPL,即特权级;第2位是TI(Table Indicator),用来表示选择子是GDT还是LDT的索引;3~5位是描述符的索引值,就是数组下表
PS:我们注意到索引一共是13位,也就是说一个GDT最多有2^13=8192个表项
LDT(Local Descriptor Table)是局部描述符,一个任务对应一个LDT,但它在现实中应用很少,我们的系统中也未用到LDT
GDTR(Global Descriptor Table Register)是用来指向GDT的寄存器,GDT存储在内存中,GDTR存储的则是GDT的地址。

如图所示是GDTR的结构,48位寄存器前16位是GDT以字节为单位的界限,后32位是GDT在内存中的起始地址
GDT界限范围有16位,也就是占有2^16个字节,而一个表项占有8字节,一个GDT一共可以存储2^16/8=8192个表项,和上面结论相符合
ldgt(load Gloabal Descriptor Table)指令用来加载GPT,一般情况下从实模式进入保护模式我们需要使用命令ldgt来初始化GPTR,不仅如此,在保护模式中我们也可以使用ldgt命令来修改GPTR的值。ldgt的指令格式是:lgdt 48位内存数据
段描述符与内存的关系
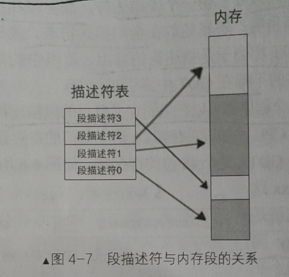
如图可知,段描述符指向内存的各个地方。但是GDT的第0个段描述符是不可用的,因为GDT是用选择子来索引的,如果选择子忘记初始化就默认为0,这样选择子相当于索引到不可用的段描述符,而不会索引到其他内存空间。
打开A20地址线
实模式下的地址回绕
实模式下有20根地址线,也就是说最多可以索引1MB空间。实模式下我们用
16位段基址:16位偏移量的形式来计算物理地址,我们发现假设16位段基址是0xFFFF,16位地址量是0xFFFF,最终计算得到的物理地址应该是:0xFFFF*16+0xFFFF=0x10FFEF,我们发现这个地址已经超出了20位地址线所能传输的最大范围0xFFFFF。那当我们在实模式下访问超出0xFFFFF物理地址范围的空间时会发生什么事吗?其实并不会发生太糟糕的事,由于硬件原因,超出20位地址线的位将被舍弃,当你访问超过0x100000时就相当于访问0x00000,访问0x10FFEF时就相当于访问0x0FFEF。这个特点就叫做地址回绕。32位CPU也要兼容地址回绕
实模式下地址回绕的特性被许多程序员视为优点加以利用编程,但是保护模式却没有地址回绕这个问题。所以为了满足32位CPU必须兼容保护模式和实模式的特点,我们必须让32位CPU也要具备可以自由使用地址回绕的特点。
我们知道32位CPU有32位的地址线,IBM在键盘控制器上的一些输出线来控制第21根地址线(A20)的有效性,成为A20Gate。
如果A20Gate=1,当访问0x100000~0x10FFEF之间的地址将会正常访问
如果A20Gate=0,当访问0x100000~0x10FFEF之间的地址将会触发地址回绕特性
打开A20地址线
因此,当我们想从实模式进入保护模式时,我们必须打开A20Gate才能让保护模式的程序正常运行,打开A20地址总线的方式是将端口0x92的第一位置1,代码如下:
in al,0x92 or al,0000_0010B out 0x92,al
保护模式的开关,CRO寄存器的PE位
想从实模式进入保护模式,我们还差最后一步。控制寄存器CRx是CPU的窗口,既可以用来展示CPU内部状态,又可以用来控制CPU运行机制。这次我们要用到CR0寄存器的PE(Protection Eanble)位,CR0寄存器构造如下图所示:
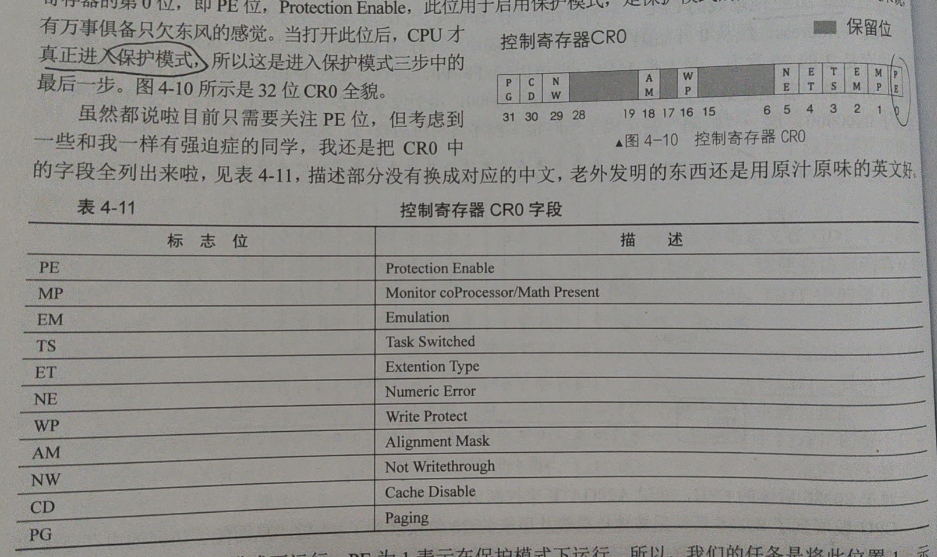
右上方是CR0格式位,下方则是对每个位的描述,我们目前只需要关注PE位就行了,将PE位置1,让CPU知道我们要进入保护模式了,代码如下:
mov eax,cr0
or eax,0x00000001
mov cr0,eax
为什么使用远跳转指令来清空流水线
我们使用jmp dword SELECTOR_CODE:p_mode_start来更新流水线,究竟是为什么?
段描述缓冲寄存器未更新
32位CPU兼容保护模式和实模式,段缓存寄存器在实模式下和保护模式下都有用。实模式下:段描述缓冲寄存器用于缓存段基址,保护模式下:段描述缓冲寄存器缓存段描述符。只有当CPU重新引用一个段后,段描述缓冲寄存器才会更新。
当我们从实模式到保护模式后,我们的段描述缓存寄存器存在的还是实模式下用的20位段基址,这当然是不行的。所以我们指令跳转到
SELECTOR_CODE:p_mode_start相当于重新引用一个段,让它更新。流水线中指令译码错误
从实模式到保护模式,一开始我们是16位指令,后来是32位指令。因为CPU的流水线技术提前被加载进流水线的32位指令可能会被译码错误成16位指令。因此我们使用无条件跳转指令jmp,跳转过后会自动清空流水线,避免译码错误。
dword
dword则是让编译器将
p_mode_start当成32位操作数处理保证得到正确的地址
分页机制
为什么要分页?
我们只有4GB的内存空间,但我们想让每一个程序都拥有(或者以为自己拥有)4GB的内存空间,于是有了分页机制。
分页机制是在内存分段的基础上进行的
分页机制的核心思想是:通过映射,可以使连续的线性地址与任意物理内存地址相关联,逻辑上连续的线性地址其对应的物理地址可以不连续
一个程序它申请4GB的内存空间,实际上它并不是每时每刻都需要全部的4GB内存空间,大部分时候它都只在使用其中一两小部分的内存空间。我们将该4GB的内存空间分成好多个等大小的块(页),然后根据一个映射规则将当前有用到的块映射到物理内存中,这样4GB的物理内存就可以同时被接受多个程序享用。
一级页表
分页
内存分段机制下的内存访问示意图如下:
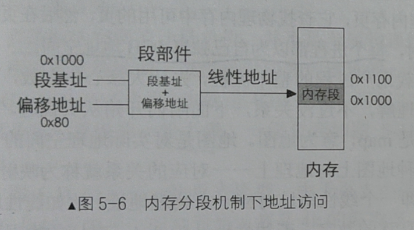
我们在实模式下提供段基址,或者是在保护模式下提供的选择子加上另外提供的偏移量,在段部件的处理下形成了线性地址。在还没开启分页机制的情况下,这个线性地址就是真实的物理地址
分页机制下的内存访问示意图如下:
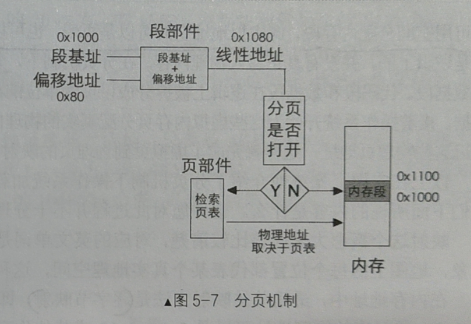
如果打开了分页机制,线性地址还要经过页部件(负责检索页表的部件)的处理,然后才变成了真正的物理地址。我们把没经过页部件处理的线性地址叫做虚拟地址
分页机制的作用在于:
将线性地址转换成物理地址
用大小相等的页代替大小不相等的段
如下图所示:
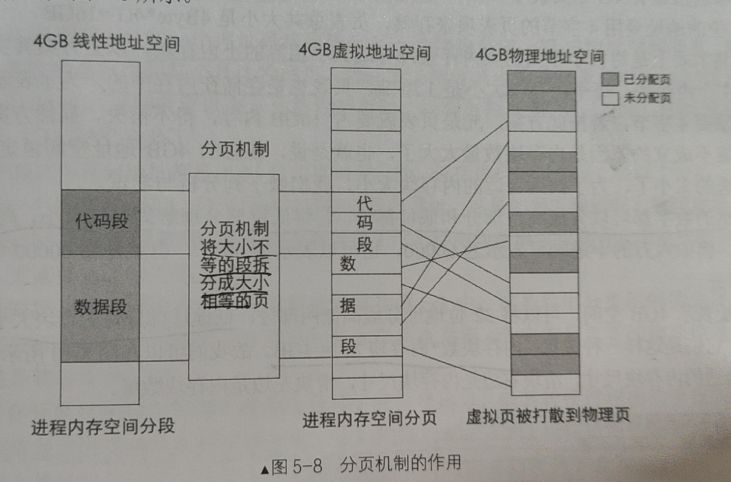
在分段的基础上,将虚拟空间中的段划分为一块块大小相等的页然后映射到任意物理地址空间里
映射
我们把存储映射关系的数据结构叫做页表(页表也是存储在内存中),页表中的每一项叫做页表项(记录着页对应的物理地址),一个页表项需要4字节的大小来描述,页表与物理内存之间的关系如下图所示:
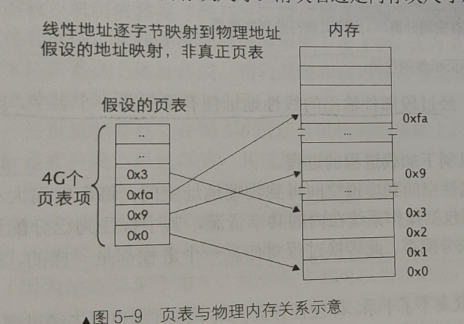
线性地址和物理地址之间的映射有多种可选择的方案
比如最简单的是逐字节映射,虚拟空间中的每一个字节对应到物理空间地址上的每一个字节,那么4GB的虚拟空间对应的页表就得有4G个页表项,每个页表项需要4字节,则一共需要16GB空间大小的页表。为了扩展4GB的内存空间而使用了16GB内存空间这明显是不合适的,所以我们要找到一个合适的映射关系,使得分页机机制即能实现,也不会占用太大的额外内存空间。
最终决定的合适的映射方案是:每4KB大小的空间作为一页。也就是说4GB的内存空间一共可以划分成4GB/4KB=1M个页,一张页表就得含有1M个页表项,总大小为4MB(就空间耗费而言可以接受)
从线性地址到物理地址
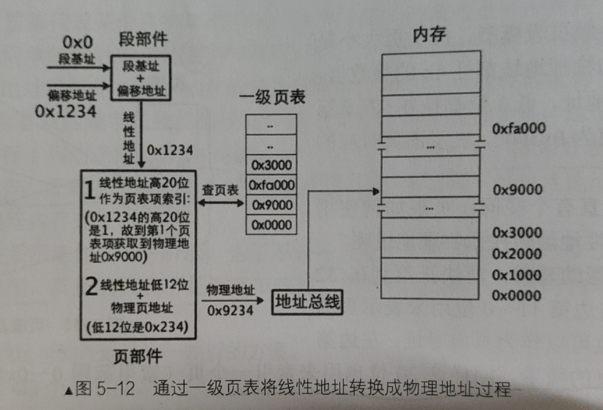
现在我们如何从线性地址定位到物理地址呢?
首先页表是存在内存中的,页表的起始物理地址我们会放置在CR3控制器中,这样CPU就知道页表的位置了
然后我们要定位到具体的页表项,
取出线性地址的高20位作为索引*4(因为每个页表项占据4字节)+CR3中页表的起始物理地址=目标页表项的地址。找到了页表项也就相当于找到了该页对应的物理地址最后我们把
线性地址低12位作为偏移量+页物理地址=线性地址对应的真正物理地址
线性地址到物理地址转换的全过程如图所示:
二级页表
一级页表的大小有4MB,这个大小虽然可以接受但不够灵活,我们需要保证内存里有一整块连续的4MB空间。而且每一个进程对应一个页表,当电脑同时运行多个进程的同时页表就会占据很大的空间。我们希望能更节约空间,于是有了二级页表机制
二级页表将原本一共有1M个页表项的大页表分成1k个每个包含1K个页表项的小页表。小页表的空间是1K*4Byte=4KB,刚好小页表的大小也是一个页。这样这些1K个小页表就可以灵活得分散到内存空间各个地方里了。但是为了找到这些小页表,我们需要一张页目录(页表的页表),页目录的每一项叫做页目录项(一个页目录项大小也是4字节,一共是1K项),每一项记录着对应小页表的物理地址。真巧!页目录的大小刚刚好也是1K*4Byte=4KB(就是一个页的大小)。
二级页表内存分布如下图所示:
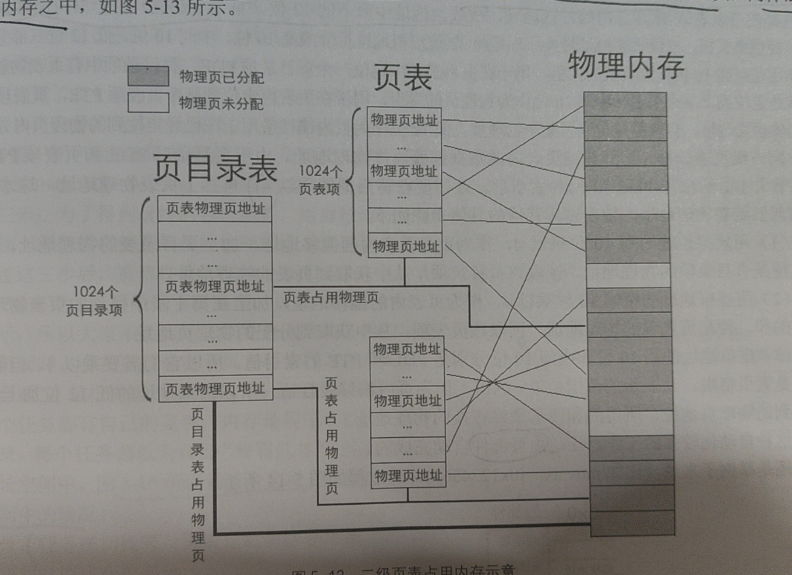
这样做有什么好处吗?我们发现二级页表并没有让真正的页表所占用空间变少(只是把它们拆散了),反而多出了一个4KB大小的页目录。但实际上,这样做以后,小页表不仅不需要连续的大空间,而且也可以像普通的页一样在使用频率少的情况下被从内存换到磁盘上,只在需要用的时候才取回来。用4KB空间换取的灵活能带来更多好处。
如何从线性地址定位到物理地址(二级页表)?
同样也是放在内存中的页目录变成了起点,页目录的起始物理地址我们会放置在CR3控制器中,这样CPU就知道页目录的位置了
我们先取线性地址的高10位*4(页目录项也是4字节)定位到页目录中相对应的页目录项,找到了页目录项就相当于找到了对应页表的物理地址
将线性地址的中间10位*4+对应页表的物理地址找到了页表项,找到了页表项就相当于找到了页的物理地址
将线性地址的最后12位+页的物理地址=线性地址对应的真正物理地址
线性地址到物理地址(二级页表)转换的全过程如图所示:
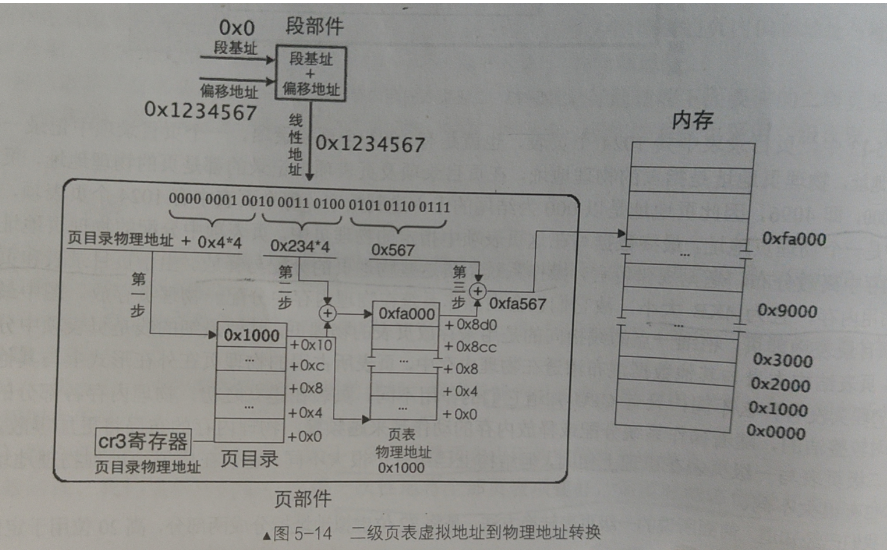
页目录项、页表项以及CR3格式
页目录项和页表项的格式如下:

页目录基址寄存器(CR3)格式如下:

为什么页目录项的页表物理地址只有20位而不是32位?因为内存是以4KB每页为单位划分的,因此只要20位地址就可以找到对应的页表了
为什么页表的物理页地址也只有20位?这20位足够索引到内存中的对应页了,剩下的12位是段内偏移量由线性地址的最后12位组成
AVL是Available位,表示可用,是给软件看的。操作系统可以不管该位
G,全局位。G=1,则代表缓存在TLB(页表缓冲寄存器)中了,可以不用经过地址转换,直接通过TLB取值
PAT(Page Attribute Table)此位比较复杂,直接置0即可
D(Dirty)脏位,CPU对一个页进行写操作时,对应的页表项D位置1,表示该页已被修改过
A(Accessd)访问位,每当CPU访问过该页时,对应的A位置1。过一段时间后由操作系统同一置0,操作系统可以通过置0的频率来判断该页是否被经常使用
PCD(Page-level Cache Disable)页表高速缓冲禁止位,别管那么多,置0就行
PWT(Page-level Write-Through)页级通写位,别管那么多,置0就行
US(User/Supervisor)普通用户/超级用户位,为1表示User级,任意特权程序可访问。为0表示Supervisor级,特权级别3的程序不可访问
RW(Read/Write)1表示可读可写,0表示可读不可写
P(Present) 存在位,P=0表示该表不在物理内存中
启用分页机制的步骤
启用分页机制要做三件事:
准备好页目录以及页表
将页目录地址写入控制寄存器cr3
寄存器cr0的PG位置1
什么是可以自举的分页模型?
当我们想要访问一个物理地址时,我们给出的线性地址将会经过页部件的转换(页目录和页表的查询)后指向真实的物理地址。
现在有一个问题,如果我想要在开启分页机制的情况下修改现有的分表/页目录,我该怎么做?
你可能已经发现问题所在了,我们给出的线性地址都是经过页表/页目录的映射后才指向真实的物理地址。但是如果我想访问页表和页目录,我给出的地址也是会经过页表/页目录的映射后指向其他地方。所以我们需要可以自举的分页模型,也就是说给出的线性地址经过经过页部件转换后可以真正指向目标页表/页目录的物理地址。
接下来我们为loader构建的分页模型就是一个可以自举的分页模型
加载内核并初始化
加载内核并初始化的步骤
我们将告别汇编,用C编写内核文件kernel.bin,用C编写将会和之前有以下区别:
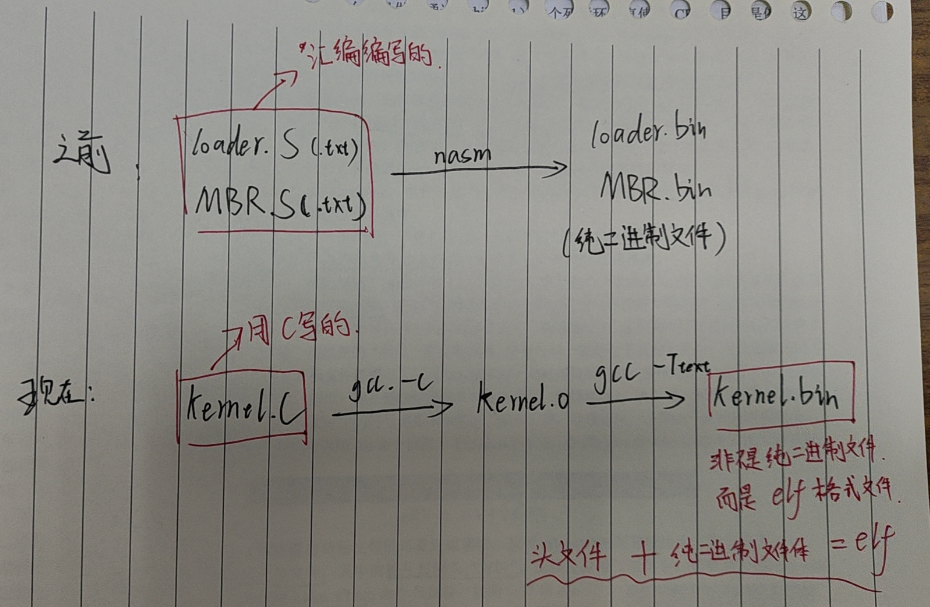
加载内核要做的事如下:
用C编写并使用gcc编译链接得到kernel.bin文件,然后用dd指令将kernel.bin文件放到磁盘里
修改loader.S,负责把kernel.bin文件加载到合适的位置(执行完第三步kernel.bin就没用了)
修改loader.S,负责初始化内核,即通过elf头文件信息 将kernel.bin文件里的每个段分别放置在elf头文件指定位置(elf中包含头文件,我们总不能把头文件里的元信息也放置到CPU上执行,所以需要拆解)
跳转到kernel的程序入口地址,loader.S交出最后一棒接力棒
内核文件的内存布局
我们要讲内核加载到内存的哪里?请看下图低端1MB内存布局里三个打勾的位置:
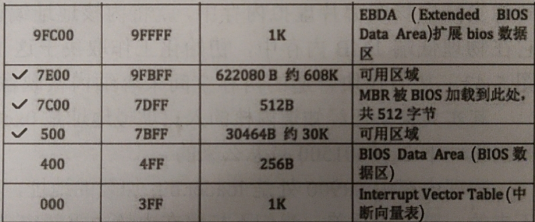
三个打勾的位置将会是我们内核存放的地方(加载在0x7c00的MBR的工作已经做完了,可以被覆盖。加载在0x900的loader里面包含gdt设置,不能被覆盖),从上述加载内核的步骤看我们需要两个地方来存储内核。
第一个地方存储kernel.bin(对应第2步)
第二个地方存储被loader.S处理后的真正的内核映像文件(对应第三步)
kernel.bin应尽量位于高地址,给不断增长的kernel映像文件腾出空间。预计kernel.bin不会超过100kb,计划存储在0x70000(0x70000~0x9fbff有190KB)。
kernel被处理后的映像文件应该尽量放在低地址同时不能覆盖loader。预计loader大小不会超过2000字节,0x900+2000=0x10d0,取一个整数为kernel的映像文件地址0x1500。
上述我们说的都是物理地址,由于我们开启了分页机制后,写代码时里要将物理地址转化为虚拟地址,相应的两个虚拟地址分别是0xc0070000和0xc0001500
在加载完内核后,我们还需要选择一个新的地方作为内核代码的栈顶,可用空间的顶部0x9fc00作为栈顶是最合适的。但是由于pcb(后面章节讲)要求4KB对齐,所以栈顶既要接近0x9fc00又要是4KB的整数倍,所以我们选择了0x9f000作为内核代码的栈顶,转化为虚拟地址即是0xc009f000
elf文件格式
elf文件布局
elf文件=二进制可执行文件+头文件(存储元信息)
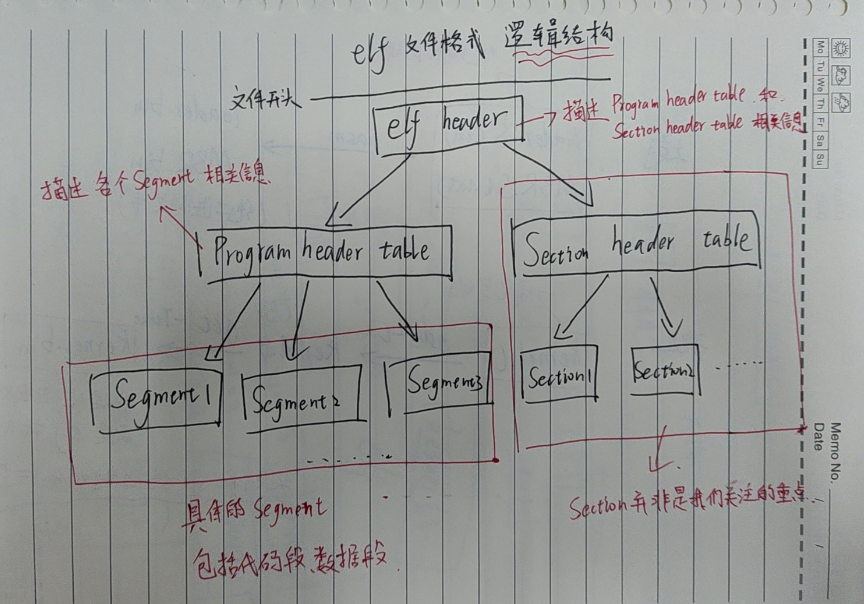
一个elf文件的逻辑布局如下图:
物理布局如下图:

关于这两图我们要讲几点:
Section和Segment的区别:
Section是写代码时为了更清楚的逻辑划分,程序员将代码主动划分为一节一节。(汇编语言中的section、segment关键字本质上划分的都是节)
Segment是编译器将相同类型的Section集合在一起形成了段,如代码段、数据段。(经过编译器链接后,我们才称为段)
我们关注的重点:
大部分的Section经过编译器链接后成为了Segment,我们关注的重点在Segment,我们所要做的就是根据elf头文件的指示,将每一个Segment放到它该去的地方
elf header结构
elf格式的数据类型(它们就和int、double一样,只关注字节大小就好了)

elf header的数据结构(该数据结构的布局是重点,我们关注每个字段的字节偏移,这样loader.S就可以读取它需要的字段了)

elf header具体数据成员意义描述(重在会查表应用,而且大部分时候我们只使用其中关键的几项:e_phoff、e_phentisize、e_phnum):
e_ident

e_type
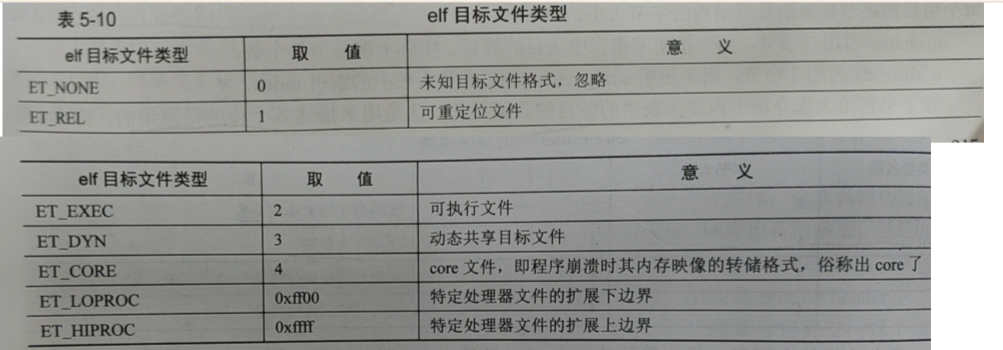
e_machine
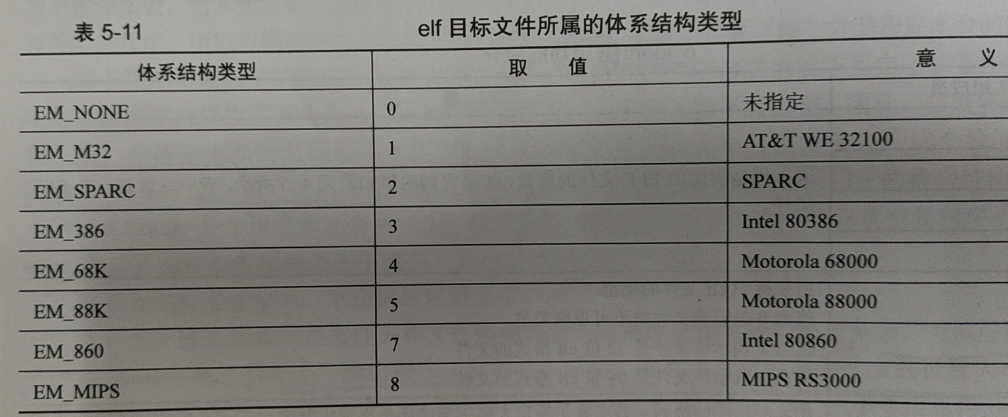
others

program table header结构
program table header的数据结构(该数据结构的布局是重点,我们关注每个字段的字节偏移,这样loader.S就可以读取它需要的字段了)

program table header的成员描述(重在会查表应用,而且大部分时候我们只使用其中关键的几项:p_offset、p_vaddr、p_mensz):
p_type
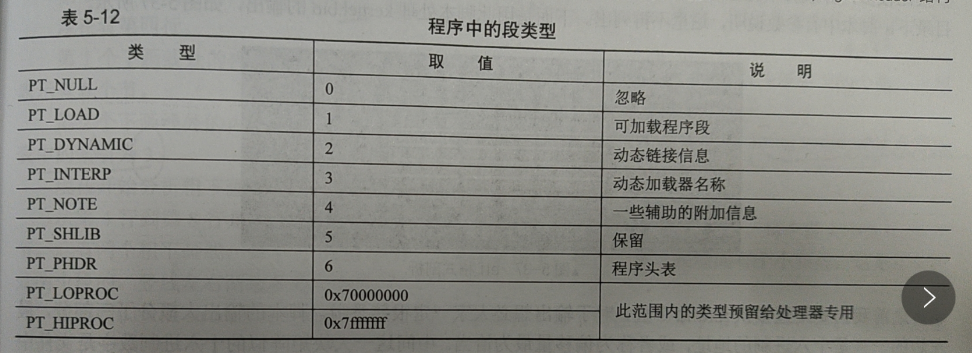
p_flags
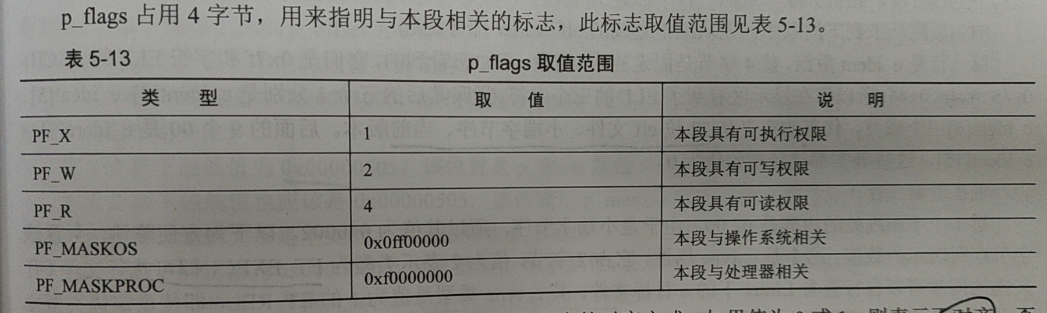
others

实例:请参照操作系统真相象还原P218-5.3.4;我们可以使用命令readelf -e '文件名'来查看一个elf文件的头的具体数据,也可以使用hd '文件名'来查看一个elf文件的十六进制形式
完整源代码
见连接如下: